
友好定价、专业客服支持、正版软件一站式服务提供
工作日:9:00-22:00

发布时间:2023-05-25
浏览次数:0
一、背景
(以下简称SR)是新一代快速全场景MPP数据库,可满足多种分析需求,包括OLAP多维分析、定制报表、实时数据分析; 随着公司WOS的升级战略,BI选择了WOS系统中的SR作为数据分析层数据库; 在SR应用实践过程中,随着越来越多的商家迁移到WOS,SR中的数据急剧减少,一些显存不足的问题也逐渐暴露出来,主要有以下问题:
字段模型表的常驻显存不断减少,最多占用可用显存的16%。 太多了,270张表160W+表,大概90%大于100M。
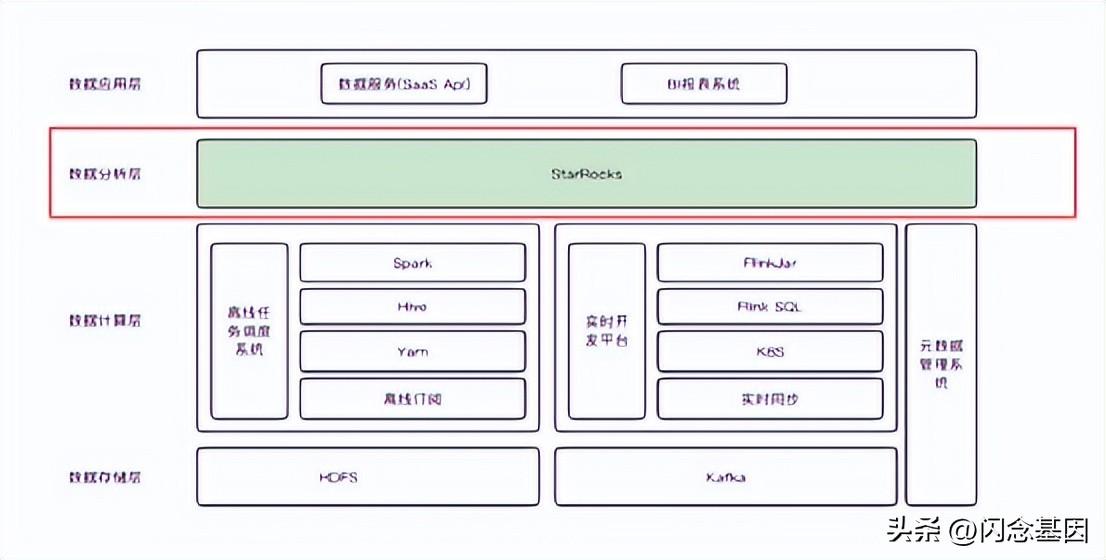
二、问题分析
2.1 第一个问题是场模型常驻显存大,查看场模型官方介绍。
在分析数据库中查询字段模型后,主要用于实时分析。 实时分析主要是当天的数据,数据量不会太大。 根据官方描述,现场模型数据具有冷热特性。 对实时分析DB表进行查询:发现三张表的数据总量约为17GB。 在查询三张表的DDL时,发现三张表没有分区,所以三张表的数据都会加载到显存中,最终导致字段模型常驻显存很大。
2.2. 太多了,个体数据量小
官方pair定义:在同一个中dnastar可以在64位系统上用么, key的hash值相同的数据以多副本的方式冗余存储,是数据平衡和恢复的最小单位。 数据库的副本由单独的本地存储引擎管理,数据导入和查询最终下沉到涉及的副本。
官方建议:建议单个分区的原始数据量不要超过100GB,每个数据文件的大小在100MB到1GB左右。
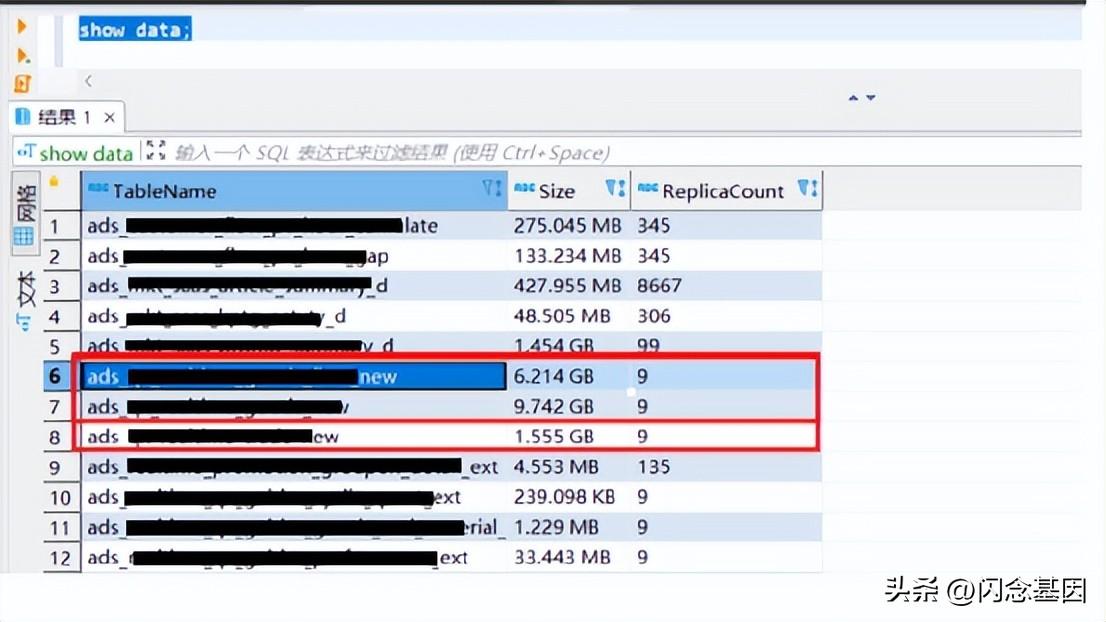
执行以下语句:
SHOW DATA;显示数据; 分析库中的表,存在以下问题:
大多数表按天分区,有 3 个副本和 3 个桶。 目前有些表的数据量很小,而且(shard个数)很多,所以每个shard的数据量极小。 以一张表为例,=3*=3*dd (2019-12-20 to 2022-07-08) = 5598,计算出每比特数据量约17Kb,与官方推荐有巨大差异,太多的元数据被浪费了。
目前我们大多使用更新模型,太多,多次导出数据,数据版本多,速度慢,导致表的存储容量远小于实际存储容量。
3.优化方案
3.1. 第一个问题场模型常驻显存大
优化方案:3张表改为分区表,分区生命周期减少,只保留近10天的数据。
优化执行步骤如下:
--第一步停止实时任务
--第二步新建bak表
CREATE TABLE realtime_sr_db.`ads_xxx_d_bak` (
`id` bigint(20) NOT NULL COMMENT "id",
`dd` date NOT NULL COMMENT "日期",
) ENGINE=OLAP
PRIMARY KEY(`id`,`dd`)
COMMENT "实时xxx明细"
PARTITION BY RANGE(`dd`)
( START ('2022-07-12') END ('2022-08-25') EVERY (INTERVAL 1 DAY) )
DISTRIBUTED BY HASH(`id`) BUCKETS 3
PROPERTIES (
"replication_num" = "3",
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "day",
"dynamic_partition.time_zone" = "Asia/Shanghai",
"dynamic_partition.start" = "-10",
"dynamic_partition.end" = "2",
"dynamic_partition.prefix" = "p",
"dynamic_partition.buckets" = "3",
"in_memory" = "false",
"storage_format" = "DEFAULT"
);
--第三步迁移数据
INSERT INTO realtime_sr_db.ads_xxx_d_bak SELECT * FROM realtime_sr_db.ads_xxx_d where topicdate>'2022-08-08';
--第四步更换表名称
ALTER TABLE ads_xxx_d RENAME ads_xxx_d_bak_1;
ALTER TABLE ads_xxx_d_bak RENAME ads_xxx_d;
--第五步删除表
DROP TABLE ads_xxx_d_bak_1;
--第六步 开启实时任务3.2. 第二个问题:太多,个体数据量小
优化方案:整理出需要整改的132张表,分三批进行优化。 第一批整改数据量大于1GB的表53张,第二批整改数据量大于20G的表,第三批整改大于20G的表;分别对每批表进行评估,将分区改为根据数据量按周、月、年分区。
评价规则:
1.查看分区数据使用详情
执行以下语句查看表格短发区域的情况:
SHOW PARTITIONS FROM ads_xxx_dwm;根据详细的分区数据,该表目前是按天分区的。 当每个分区的数据分桶时,每个桶的数据量远大于官方推荐的100M。
2.分区合并规则
根据分区数据量判断,比如右边的DDL中,2021年之前的历史数据量必须按年分区才能满足小于100MB的条件,所以2021年之前的数据可以按年分区; 2021-01-01至2022-06-01期间的数据按月分区满足小于100MB的条件,这部分数据可以按月分区; 这样就可以根据数据量来确定WEEK和DAY分区的时间段了。
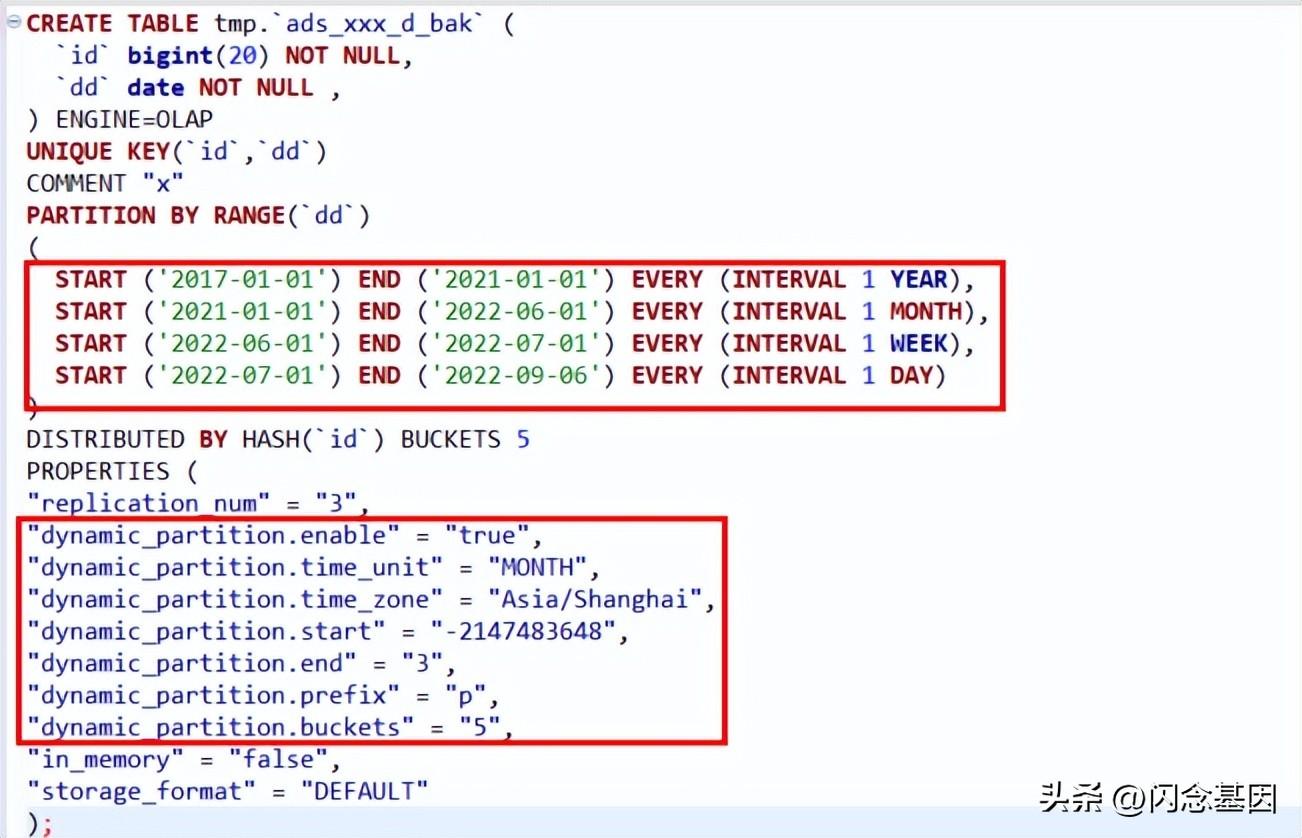
优化执行步骤如下:
--第一步新建新结构bak表
CREATE TABLE `ads_xxx_d_bak` (
`id` bigint(20) NULL COMMENT "ID",
`dd` date NULL COMMENT "数据日期",
) ENGINE=OLAP
UNIQUE KEY(`id`, `dd`)
COMMENT "xxx"
PARTITION BY RANGE(`dd`)
( START ('2021-01-01') END ('2023-01-01') EVERY (INTERVAL 1 YEAR),
START ('2023-01-01') END ('2023-02-01') EVERY (INTERVAL 1 MONTH)
)
DISTRIBUTED BY HASH(`id` ) BUCKETS 3
PROPERTIES (
"replication_num" = "3",
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "MONTH",
"dynamic_partition.time_zone" = "Asia/Shanghai",
"dynamic_partition.start" = "-2147483648",
"dynamic_partition.end" = "1",
"dynamic_partition.prefix" = "p",
"dynamic_partition.buckets" = "3",
"in_memory" = "false",
"storage_format" = "DEFAULT"
);
--第二步迁移数据到bak表
INSERT INTO tmp.ads_xxx_d_bak SELECT * FROM tmp.ads_xxx_d;
--第三步更换表名称
ALTER TABLE ads_xxx_d RENAME ads_xxx_d_bak_1;
ALTER TABLE ads_xxx_d_bak RENAME ads_xxx_d;
--第四步删除表
DROP TABLE ads_xxx_d_bak_1;4.优化疗效比较 4.1. 主键模型优化后:每个BE平均占用显存从7G增加到1G左右,比之前平均增加了6G,增幅85%。
4.2. 过度优化:
经过两轮分区合并,数量从整改前的160W+增加到30W+,增幅约81%。 显存从原来平均每单位10.9GB下降到平均每单位8.9GBdnastar可以在64位系统上用么,增幅约为18.34%。
优化后FE和BE显存变化:
FEjvm堆:
之前FE的JVM heap占用高达18G,优化后峰值为4G。
BEMem:BE的显存占用,在集群级别,常驻显存增加了55g。
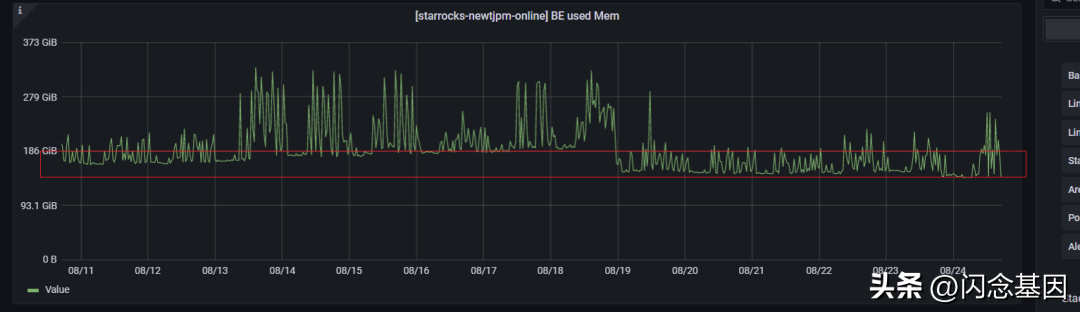
优化推理总结:
经过4轮优化,在BE对显存使用的集群层面,常驻显存增加了55GB,FE节点的JVM堆内存使用量增加了77.77%,数量增加了约81%。 集群的健康状况有所改善。
如有侵权请联系删除!

官方公众号
Copyright © 2023 江苏优软数字科技有限公司 All Rights Reserved.正版sublime text、Codejock、IntelliJ IDEA、sketch、Mestrenova、DNAstar服务提供商
Copyright © 2023 江苏优软数字科技有限公司 All Rights Reserved.正版sublime text、Codejock、IntelliJ IDEA、sketch、Mestrenova、DNAstar服务提供商
13262879759
微信二维码