
友好定价、专业客服支持、正版软件一站式服务提供
工作日:9:00-22:00

发布时间:2025-01-27
浏览次数:0
1。评论:“一千万级数据和十亿级数据”是关键
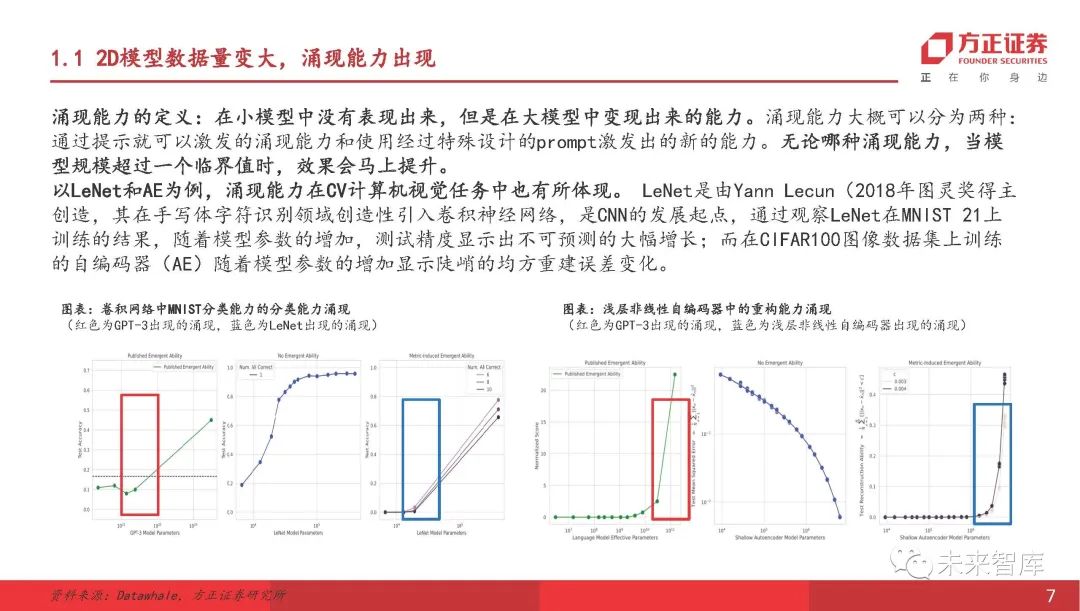
2D模型数据的数量增加,并且出现了紧急功能。
出现能力的定义:在小型模型中未显示但在大型模型中实现的能力。突然的能力可以大致分为两种类型:可以通过提示和通过使用特殊设计的方法刺激的新能力来刺激的紧急能力。无论出现能力如何,当模型大小超过临界值时,效果将立即改善。以Lenet和AE为示例,出现功能也反映在CV计算机视觉任务中。 Lenet是由Yann Lecun(2018年奖的获奖者)创建的。他在手写角色识别领域创造性地引入了卷积神经网络。这是CNN开发的起点。通过观察MNIST 21的LENET训练的结果,随着模型参数的增加,测试精度显示出大量且无法预测的增加。当在图像数据集上训练的自动编码器(AE)显示陡峭的平方重建误差随着模型参数的增加而发生变化。
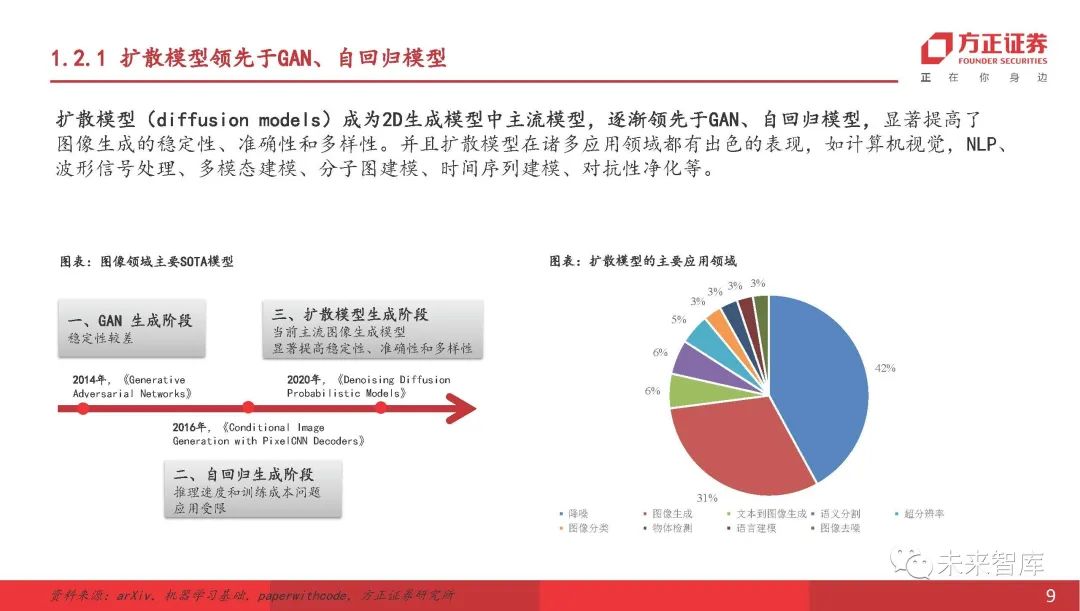
扩散模型领先于GAN和自回归模型
扩散模型()已成为第二代模型中的主流模型,逐渐领导GAN和自回归模型,从而显着提高了图像生成的稳定性,准确性和多样性。并且扩散模型在许多应用领域中具有出色的性能,例如计算机视觉,NLP,波形信号处理,多模式建模,分子图建模,时间序列建模,对抗性纯化等。
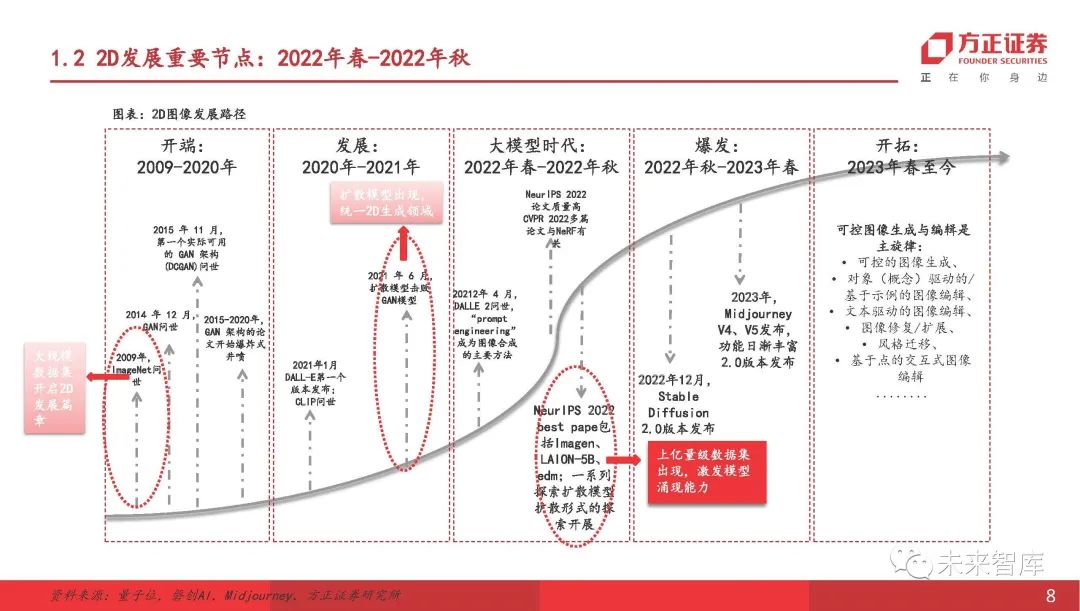
:在众包平台的帮助下完成的第一个数千万的2D数据集
数据集于2009年发布,目前包含大约1500万个注释的图像。数据集是在斯坦福大学Li 教授的领导下收集和建立的。当2009年发布时,它包含320万张图像,使其成为当时最大的2D图像数据集。开发后,数据集现在在22,000个类别中拥有大约1500万个注释的图像。来自在线图像,并在众包平台(Turk)的帮助下完成。数据集中的大量图像数据来自增长的网络平台。考虑到手动注释工作的庞大人力要求,研究小组使用了Turk(亚马逊开发的众包平台)来完成这项工作。
多种重量级算法是从数据集中诞生的
比赛每年举行,自2010年以来一直举行。2017年以后的比赛由社区主持。比赛逐渐成为全球重大赛事,2016年有172个参赛作品。在短短7年内,分类领域的错误率从0.28下降到0.03。在冠军算法(12年),(14年),(15年),SENET(17岁)和其他算法中,以扩散模型为基准,都超过了扩散模型的影响(算法的影响是以平均年度引用数量表示)。在比赛的过去赢家中,经典的深度学习网络模型,例如基于培训的VGG(2014年定位竞赛冠军)和其他人出生。多年来,冠军算法的测试错误率在6年内已从15%下降到2%,这极大地促进了计算机视野领域的发展。
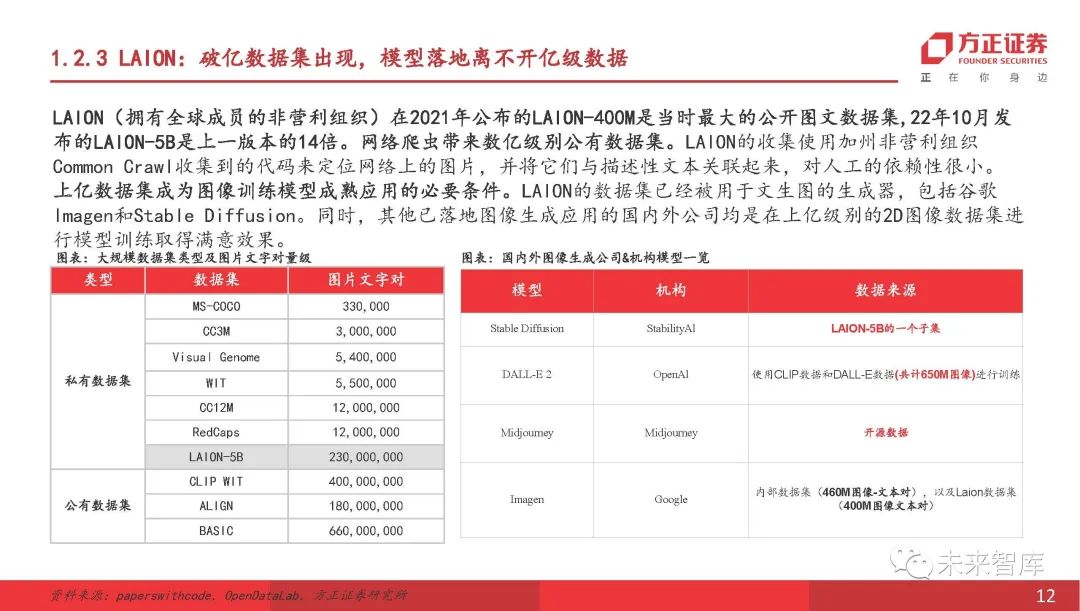
Laion:十亿级数据集的出现,模型的实施不能与十亿级数据分开
Laion在2021年发行的Laion-400M(全球成员的非营利组织)是当时最大的公共形象和文本数据集。 10月22日发布的LAION-5B是上一个版本的14倍。网络爬行者带来了数亿个公共数据集。 Laion的藏品使用加利福尼亚州非营利性爬网收集的代码在网上找到图像,并将其与描述性文本相关联,而对人工的依赖几乎没有依赖。数亿个数据集已成为成熟应用图像训练模型的必要条件。 Laion的数据集已在包括和包括在内的 Graph 中使用。同时,实施图像生成应用程序的其他国内外公司通过对数亿2D图像数据集的模型培训获得了令人满意的结果。
2。3D研究框架:它已经超过了数千万数据集,并加速了数据集的扩展。
3D开发研究框架
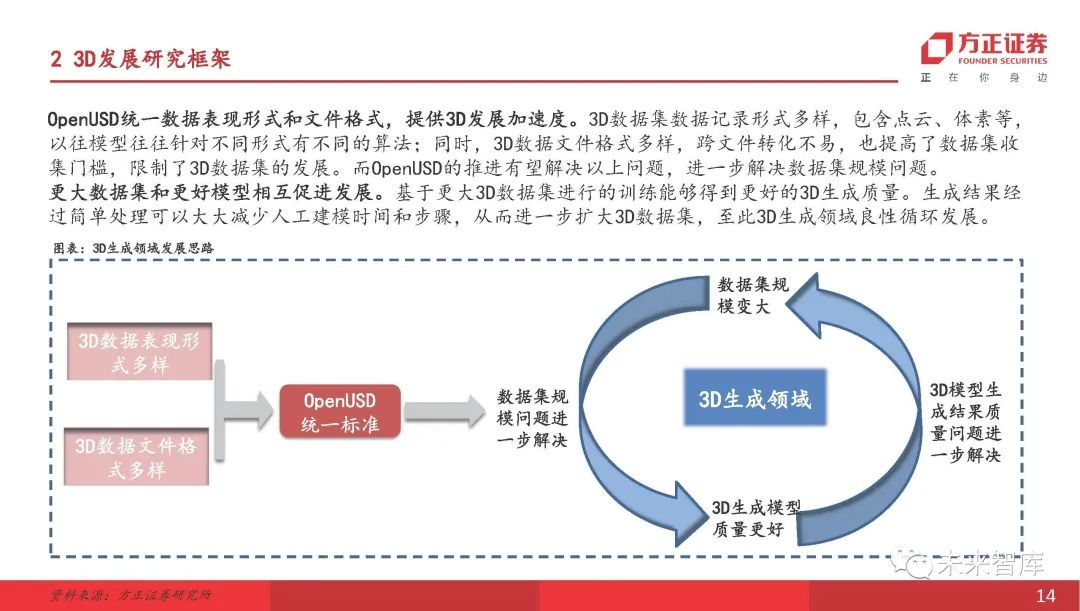
统一数据表示和文件格式以加速3D开发。 3D数据集具有各种数据记录表格,包括点云,体素等。在过去,模型通常具有不同形式的算法。同时,3D数据文件格式是多种多样的,跨文件转换也很困难,这也提高了数据集收集的阈值并限制了3D数据集的开发。预计该进步将解决上述问题并进一步解决数据集大小的问题。更大的数据集和更好的模型相互融合。基于较大的3D数据集的培训可能会导致更好的3D代质量。在简单地处理生成的结果之后,可以大大减少手动建模时间和步骤,从而进一步扩展3D数据集。在这一点上,3D生成的田地已经在良性周期中发展。
3D模型以各种方式表示,而隐式表示越来越受到关注。
主要数据表示方法:隐式表示,其中3D主流模型NERF使用INR(隐式神经表示),并受到了学术界的关注。 3D数据的世界没有一致性。当前,现有的3D数据集表示方法包括点云,网络,体素,多视图图片等。不同表示形式使用的训练路径也大不相同。隐式表示解决了明确表示的缺点,例如重叠和内存消耗,适合大分辨率场景。 INR甚至可以产生照片真实的虚拟观点。 NERF模型首次使用隐式表示来实现光真实的透视综合效应,并将隐式表示形式推向新的高度。
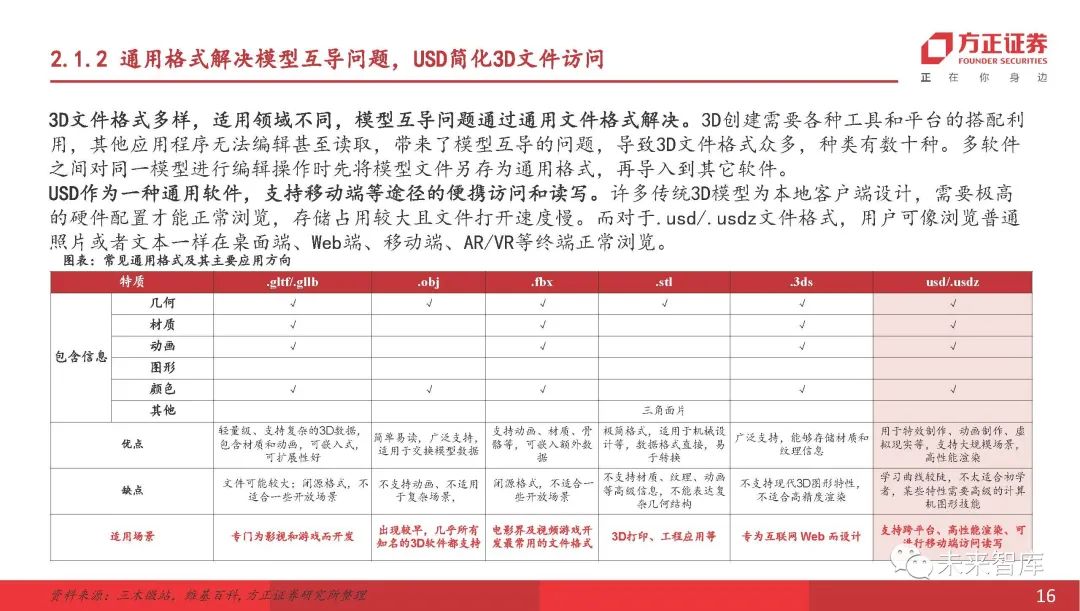
通用格式解决模型相互传导问题sketch如何导入ai文件,USD简化了3D文件访问
3D文件格式是多种多样的,适用于不同字段。相互传导模型的问题通过通用文件格式解决。 3D创建需要使用各种工具和平台,并且无法通过其他应用程序进行编辑甚至读取,从而带来了相互传导的问题,从而产生了许多3D文件格式和数十种类型。在多个软件之间编辑相同的模型时,首先以通用格式保存模型文件,然后将其导入其他软件。作为通用软件,USD通过移动终端和其他渠道支持便携式访问,阅读和写作。许多传统的3D型号都是为本地客户设计的,需要正常浏览的高硬件配置sketch如何导入ai文件,从而占用大量的存储空间和缓慢的文件打开。至于.usd/.usdz文件格式,用户可以像普通的照片或文本一样,在桌面,Web,,AR/VR和其他终端上正常浏览。
美元统一3D表示标准,联盟降低了美元使用的门槛
USD承担HTML在互联网3D时代的作用。在23日的8月8日会议上,创始人Huang 表示:“就像HTML点燃了2D 的一场重大计算革命一样,它也将开设一个协作3D和工业数字化的时代。” AOUSD继续降低学习和使用美元文件的阈值,推广美元成为3D标准。 USD是Pixar开发的一种开源格式,可以在不同工具之间创建内容和交换,但是学习曲线很陡。为了解决这个问题,致力于促进USD文件格式开发的联盟(由Pixar,Adobe,Apple,Apple,和Linux 组成的AOSD)启动了一系列有效的计划,例如™平台,用于减少用户使用的使用。
出现了第一批数据集,3D开发在“ 2020-2021”中达到2D
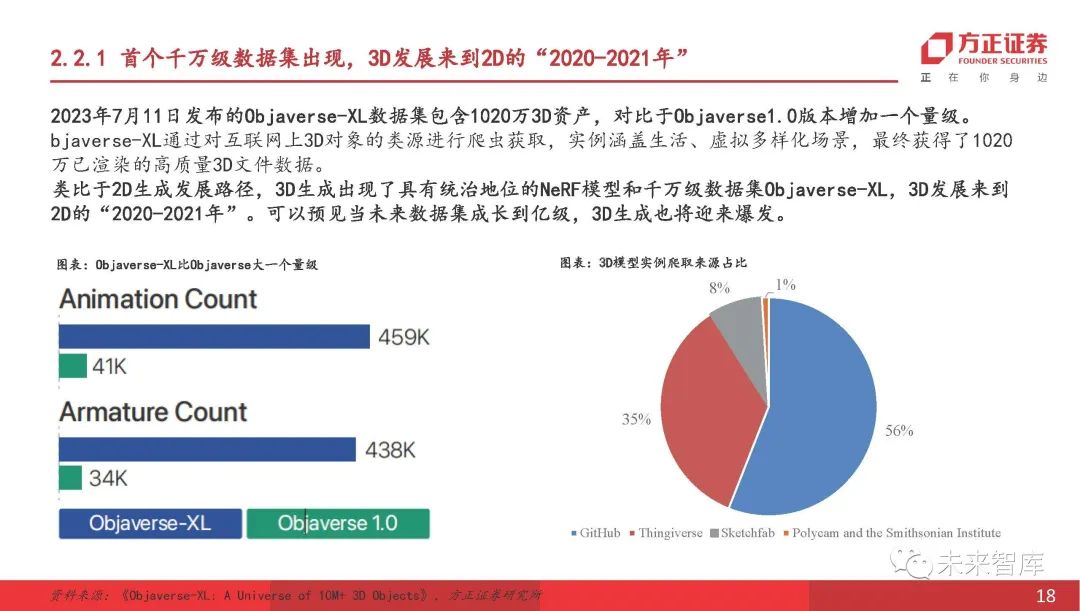
2023年7月11日发布的-XL数据集包含1020万个3D资产,这比.0版本大。 -XL通过在上爬行3D对象的类源获得。这些示例涵盖了各种生活和虚拟场景,并最终获得了1,020万个呈现高质量的3D文件数据。类似于2D代的发展路径,3D代已经与主要的NERF模型和数千万的数据集-XL一起出现。 3D开发已达到2D的“ 2020-2021”。可以预料的是,当数据集在将来增长到数亿美元时,3D代也会引起爆炸。
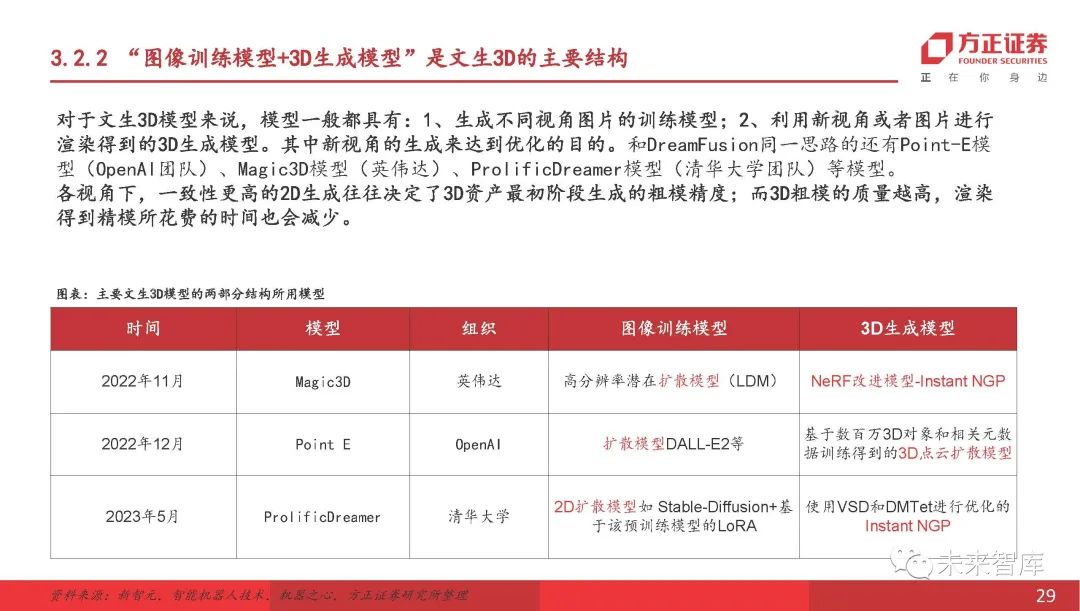
数据集越大,新的视角图片的越好,那么3D代效果就会越好。
培训了现有的算法(一种改进的NERF方法)和(图模型),发现通过基于更多数据培训,3D质量得到显着提高。随着数据集的大小变得更大,图像质量评估指数PSNR(峰值与噪声比,峰值信噪比比率,值越大表示变形越小)变得更大,表明新近新近的质量生成的透视图像更好,这有助于提高随后的3D重建的质量;比较了使用-XL(1000万级数据)和(800万级数据)训练的-XL和-XL,发现生成的3D资产的侧面和背面的完成已得到显着改善。
3D资产建模过程很长,免费示例不足
原始的3D建模过程很长,并且具有资产属性。 3D资产是游戏,动画公司等中的资产。目前,大多数示例都是通过建模软件(例如亨南和河南)手动设计的。手动建模涉及许多链接。主要过程是:查找示例 - 粗略布局 - 详细说明 - 纹理 - 渲染检查。建模过程需要大量的时间和专业知识。 3D资产很昂贵,免费实例不足。公共免费实例较少,这已成为阻碍3D数据集扩展的主要原因。在所谓的世界上最大的3D内容库平台上,每种3D车型的价格范围为3-500美元。
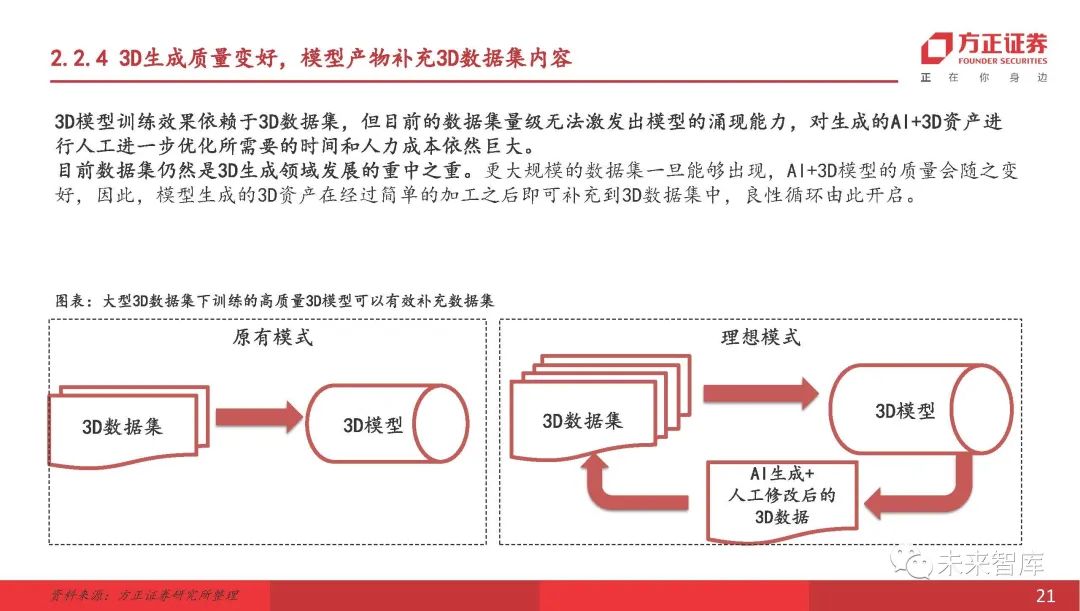
3D代的质量提高了,模型产品补充了3D数据集的内容。
3D模型训练的效果取决于3D数据集,但是数据集的当前大小不能刺激模型的新兴能力。进一步手动优化生成的AI+3D资产所需的时间和人工成本仍然很大。目前,数据集仍然是3D生成领域开发的首要任务。一旦可用的数据集可用,AI+3D模型的质量将相应提高。因此,模型生成的3D资产可以在简单处理后将3D数据集添加到3D数据集中,并且开始了良好的周期。
3。方向扩散模型 + NERF
3D一代行业指导- 3D是最终需求
目前有四种类型的3D代路,从易于到困难。 3D是最终需求,将3D资产从“专业”转变为“公共”。就发电质量,速度和实施程度而言,扫描的3D和视频生成的3D相对成熟,但它们主要受机器可访问性不佳的限制,并且没有受到广泛关注;图像生成的3D逐渐在特定情况下实现。与前三种方法相比, 3D可以直接生成文本描述的场景,甚至可以直接生成现实中不存在的事物。没有专业知识,它对普通人更加友好,并且不需要提前准备其他设备,例如扫描仪。
扫描3D:成熟的实现,可以使用手机实现
3D扫描技术结合了数字三维重建和其他技术手段,并使用三维扫描设备来对天然或合成对象进行建模,并重建真实对象的三维模型。它已被广泛用于建筑保护,CT扫描,AR/VR和其他字段。 。随着时间的发展,扫描仪的可用性和可移植性逐渐增加。 2015年,安德鲁·塔隆( )的团队完成了激光扫描和三维建模,对于巴黎的巴黎圣母院大教堂的准确性为5毫米。正在进行越来越多的扫描工作,以永久保存古物。在2020年,iPad Pro将具有用于3D扫描和增强现实的深度传感器(LIDAR),可用于使用应用程序3D Pro进行3D扫描。 iOS 12的功能是与USDZ格式共享3D模型。苹果可以通过依靠手机的相机来实现扫描建模,并且iOS和版本都已发布。
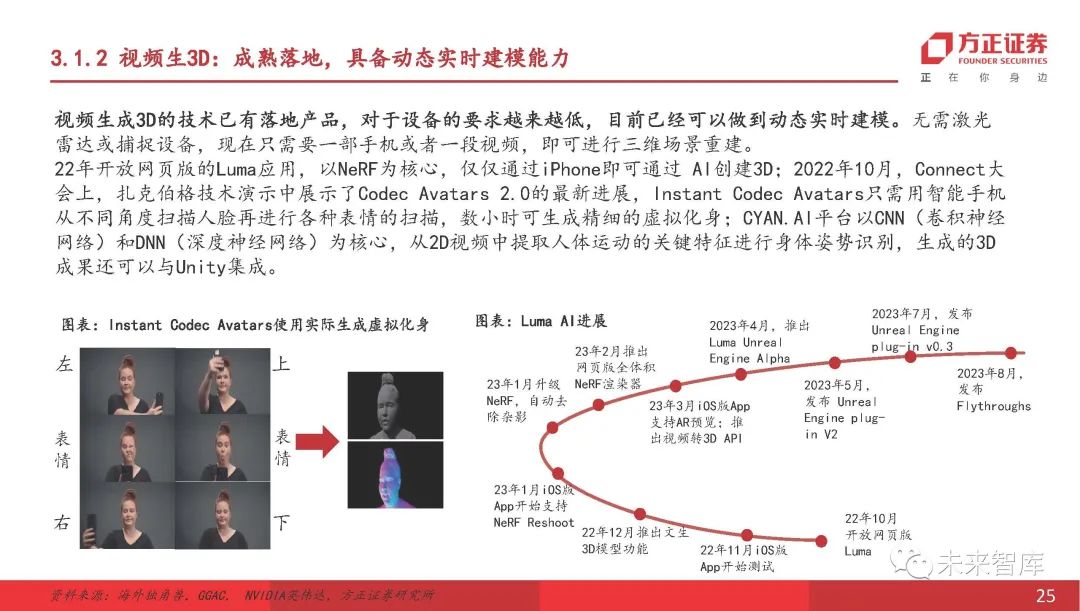
视频生成的3D:成熟实现,具有动态的实时建模功能
从视频中生成3D视频的技术已经启动到商业产品中,设备的要求越来越低。当前,可以实现动态实时建模。不需要LIDAR或捕获设备。现在,您只需要手机或视频即可重建三维场景。 Luma应用程序是2022年的开放Web版本,将NERF作为核心,可以通过AI通过AI创建3D。 2022年10月,在会议上,扎克伯格( ; CYAN.AI平台使用CNN(卷积神经网络)和DNN(深神经网络)作为其核心。从2D视频中提取人体运动的关键特征,以识别身体姿势,并且生成的3D结果也可以与Unity集成。
3D:与实际商业用途还有一定距离
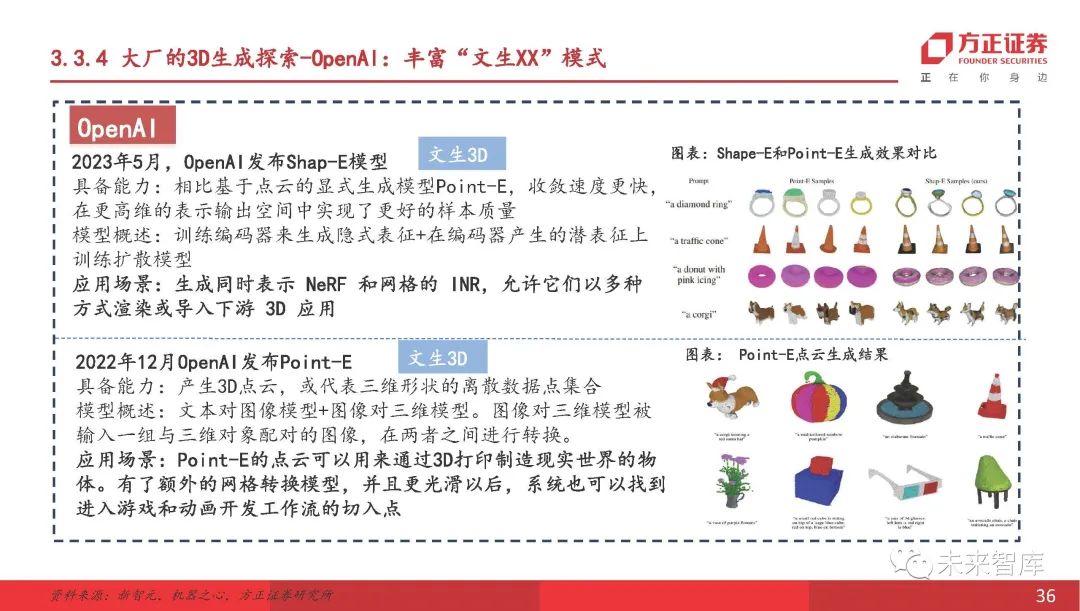
与扫描相比, 3D只需要数十个甚至几张真实场景的图片即可完成建模。从当前阶段来看, 3D模型的开发仍处于实验室阶段,与实际商业用途还有一定距离。 3D生成技术中NERF模型的本质是生成3D图像。输入是一组2D图像和相应的相机参数(包括相机位置和方向),输出是一个函数,代表3D场景中每个点的颜色和密度。技术公司一直在努力开发相应的工具。现有的应用公司包括付费申请。用户只需要上传至少一张照片即可在图片中识别对象的3D形状,并以几乎所有主流软件的格式输出给用户。此外,免费的3D模型生成工具可以与其他2D图像生成软件合作以生成3D型号,但是这些模型不能直接导入虚幻引擎或R&D引擎作为游戏角色或NPC。
3D:学术界和技术巨头非常关注该领域
很少有平台可以支持应用程序端的 3D(例如3DFY.AI,TAFI,平台)。它存在诸如长时间的问题和复杂模型的准确性较低,并且尚未达到工业生产链路中应用的标准。 2023年6月,TAFI发布了 3D发动机,该发动机受数据集的限制,其生成的内容主要是3D类人动物字符。 TAFI是3D内容和软件的领先提供商,它宣布可以从文本中创建3D字符,并利用其原始角色平台的大量3D数据集,由专业艺术家驱动的原始角色平台,以产生数十亿个3D字符变体。生成的结果可以导出到各种DCC工具,以将高质量的角色输出到流行的游戏引擎和3D软件应用程序(例如Unity,Maya,Maxon 4D等),但受培训数据来自3D的限制。角色资产,TAFI的生成内容主要集中在人形特征上。
4。成本计算:迭代次数超过10,000
第二代需要大约20-50次迭代
以2D为例,迭代越多,发电质量越高,对象就越复杂。在正常情况下,可以通过迭代2D场景约20-50次来达到要求。根据我们的实际机器测试,使用RTX 3090图形卡,同一命令生成的三组2D图像发现:2D模型的迭代速度约为每秒2.1至4.1迭代,并且速度略有提高。
3D资产计算能力 - 生成时间约为3-4小时/单位
使用3D型号,为一个场景生成3D资产,大约需要30,000个迭代,并且在RTX 3090图形卡(24GB)上运行大约需要3.3-4.2小时。根据我们实际机器测试的结果,根据算法,生成30,000次迭代的3D成品相对可行。 图像模型的过程首先通过图像过程(时间几乎可以忽略不计),然后使用NERF模型通过生成的新透视图像生成3D资产。当使用3090图形卡(24GB)并且内存使用率约为50%(即约12GB)时,将运行 3D模型。根据计算,处理后的单个场景图像的每秒迭代次数约为2.35。总优化时间(小时)=迭代次数/迭代次数每秒//。对于需要30,000次迭代的单个场景,生成3D型号需要3.3-4.2小时。
3D资产计算能力 - 发电成本约为5元/单位
使用RTX 3090图形卡在模型下迭代30,000次,生成3D资产的计算功率成本约为5元。如果您在RTX 3090上运行 3D型号,则根据RTX 3090图形卡租金为1.39元,如果它迭代每秒2.25次,需要30,000次迭代,则需要3D Asset Power COUTS = 5.15 YUAN(30,000次Yuan) /2.25次/s/60min/60sec*1.39元/小时)。将来,随着模型的发展和成熟,假设迭代速度的速度速度是当前常规级别的两倍,那么在3090图形卡上生成3D资产的计算能力将花费约2.6元。 3D资产的计算功率成本远低于市场上3D资产的购买价格,这给它带来了价格优势。在3D型号的在线内容库中,即使是简单的困难3D资产也需要大约2-15个小时,并且购买成本在3-40美元的范围内,远高于AI+3D代的成本。
该报告的摘录:
















(本文仅供参考,不代表我们的任何投资建议。如果您需要使用相关信息,请参阅原始报告。)
要获取高质量的报告,请登录[未来的智囊团]。
立即登录。请单击下面的图片输入“未来智囊团”小程序。

如有侵权请联系删除!

官方公众号
Copyright © 2023 江苏优软数字科技有限公司 All Rights Reserved.正版sublime text、Codejock、IntelliJ IDEA、sketch、Mestrenova、DNAstar服务提供商
Copyright © 2023 江苏优软数字科技有限公司 All Rights Reserved.正版sublime text、Codejock、IntelliJ IDEA、sketch、Mestrenova、DNAstar服务提供商
13262879759
微信二维码