
友好定价、专业客服支持、正版软件一站式服务提供
工作日:9:00-22:00

发布时间:2025-05-22
浏览次数:0
如需转载,发送「转载」二字查看说明
何为编码? 这可能要从一个励志的文字游戏说起。
规定中明确指出,A与B之间的交流必须遵循特定的规则,即他们只能通过数字来传达信息,并且需要将“我爱你”这一情感表达传递给对方。
于是,A萌生了一个点子,他前往书店购置了两本内容完全相同的《新华字典》,随后,他查阅了“我”、“爱”、“你”这三个字,假定它们分别位于第672页的第三个位置,第102页的第六个位置,以及第378页的第一个位置。
于是 A 将这些页码信息写在一起, 即:
B 收到了那一连串数字,便借助A提供的字典,逐一将它们转换成文字,心中充满了感动。因此,他决定拒绝A。
计算机, 数字, 字
众所周知,计算机内部仅处理数字信息,那么我们眼前的文字信息究竟是如何呈现的呢?
通过上面的故事, 我想大家已经找到答案了。
在计算机系统中,实际上存在着一种虚拟的“字典”,这本“字典”负责记录并映射“数字”与“自然字”之间的对应关系。
那么这本 “字典” 是怎么做出来的呢?
在196x年,一些美国科学家大胆地选择用8位(1字节)来编码所谓的“自然字”,然而,1字节的存储容量使得这些文字的种类不能超过2的8次方(即256)种。幸运的是,英语字母表总共只有26个字母。字符的数量加上标点符号总共不超过一百多个(少于128个,实际上7位二进制就足够表示),因此在当时看来,1字节的空间确实是绰绰有余的;结果,在256个可能的字符空间中,前128个很快就用完了,它们的对应关系是:
0至31号以及127号分配给了具备特定职能的“特殊字符”(例如,换行符、分页符、震动提示、回到行首等)。
32至126的分数分配给了字符,其中48至57代表数字,65至90代表大写字母,97至122代表小写字母,其余则为标点符号。
该映射体系后来得以持续沿用至今,形成了我们熟知的 ASCII 码,即美国信息交换标准代码。
标准ASCII码作为国际通用规范,仅占据了1个字节的前7位,同时留出了一位用于未来扩展或进行奇偶校验。
此处备有详尽的 标准ASCII码对照表 以供查阅,自然在Linux系统下,您亦可通过man命令来查阅ascii信息。
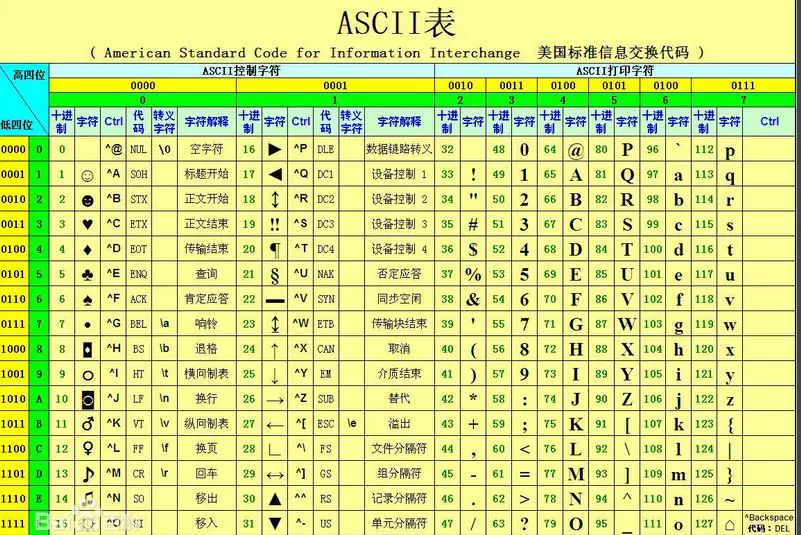
(标准 ASCII 表)
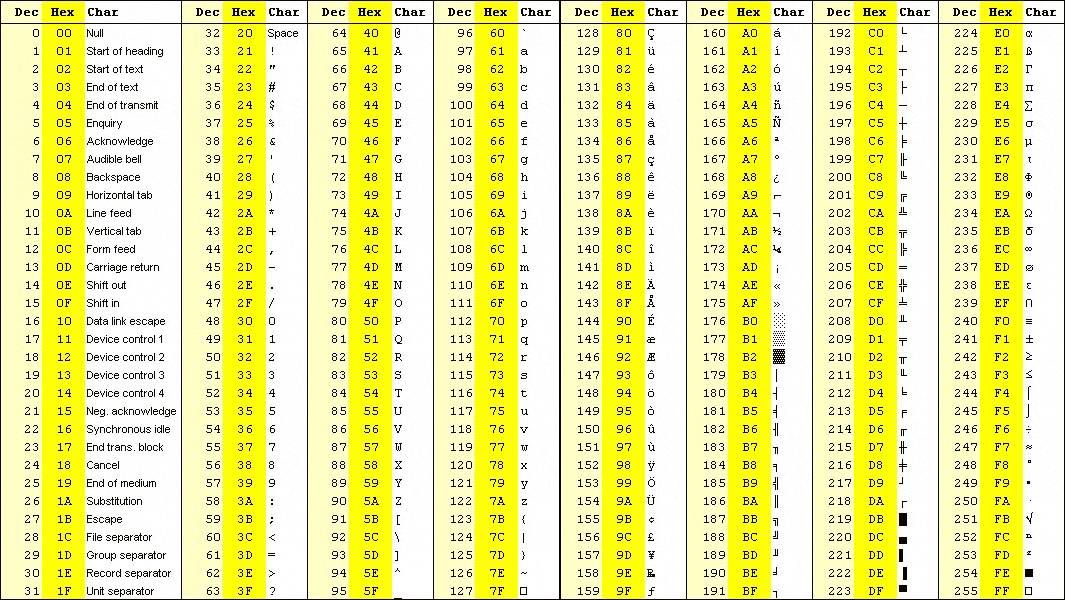
(ASCII 扩展表)
奇偶校验:
简言之,奇偶校验是一种确保数据传输准确性的技术,它包括奇校验和偶校验两种形式,分别用于检查二进制信息中“1”的数量是否为奇数或偶数,随后会将校验信息附加至数据序列末尾。
1。奇校验:
当数据中“1”的数量为奇数时,校验位应为0;若“1”的数量为偶数,则校验位需设定为1。
例如: => 奇校验 +1 , => 奇校验 +0
2。偶校验:
当数据中“1”的数量为偶数时,校验位应设为0;反之,若“1”的数量为奇数,则校验位需设置为1。
例如: => 偶校验 +0 , => 偶校验 +1
奇偶校验只能检查错误,但并不能纠正错误。
各国间混乱的编码
经过一段时日,众人察觉那128个字已显不足,便纷纷将目光转向了127号区域之后的空地。
前文已经提及,在ASCII编码中,仅前七个位(共计128个字符)被确立为国际通用标准,然而,接下来的128个位置并未设定任何具体规定或限制,亦未提供任何使用指南。
于是,轮到各个国家与公司开脑洞的时间了。
这128个后续的编码位置被称为ASCII扩展码,这一编码并非全球统一的标准。事实上,它也不可能成为国际标准,因为各个国家都有其特定的需求。然而,可用的编码位置仅有128个,若非爆发一场全球性的战争,这种情况实属罕见。在这些编码中,应用较为广泛的可能是IBM扩展字符集,亦即我们所说的cp437字符编码。
DBCS 双字节字符集
计算机在我国普及较晚,然而汉字,作为一种非拼音文字,却构成了一个极为棘手的处理难题。汉字总数超过八万,即便是日常使用频率较高的,也有三千五百多个。这对编码空间来说,无疑是一项巨大的挑战。
这个难题我想一定是东北人解决的。 因为。
东北至高法则认为:世间诸多难题,一顿烧烤往往能迎刃而解。若问题仍旧存在,那么再来一顿烧烤即可。

如果一个 ASCII 不能解决, 那就两个 !!!
实践结果证明这种做法确实行之有效,并一直保留到了今天。
为了更深入地掌握双字节字符集的相关知识,接下来我们将通过具体实例,对我国的几种主要编码体系进行详细阐述。
GB 系列: 、、 GBK、
:
该字符集是1980年首次发布的我国国家标准,属于典型的双字节字符集。它明文规定,由两个连续字节大于127的组合来表示一个汉字,若不符合此条件,则按ASCII码处理。在这两字节中,高位的字节取值范围是0xA1至0xF7,而低位的字节取值范围则是0xA1至0xFE。这两个字符组合后多出了超过8000个空位,这些空位足以容纳所有常用的汉字,而且还有额外的数学符号、罗马和希腊字母、以及日文假名等。这种编码规则与ASCII完全兼容,然而为了更好地与CP437兼容,我们不得不做出一些空间上的妥协,例如,某些字符的低位数值需要超过127,因此,其编码的可用空间相对有限。
遗憾的是,在我国当时的一位关键领导人姓名中,恰好包含了一个在字典中找不到的字。
汉卡:

早期的计算机处理能力较为有限,同时其编码规范无形中给解码过程带来了额外的压力,因此,为了提升汉字输入的效率,一种名为“汉卡”的硬件设备应运而生,该设备直接承担了编码与解码的工作sublime text 自动编码,从而减轻了CPU的负担。
但作为一款硬件, 它的流行又使得 推行不下去。
:
我国国家标准化委员会在总结了一系列缺陷之后,又推出了新的标准,尽管这一标准同样属于双字节字符集,但它与之前的标准有着本质的区别。这一新标准参照了国际标准,意味着它是面向全球化的,然而这也带来了一个直接后果,即它与旧标准不兼容。那些用真金白银购买的汉卡因此无法使用,这显然是不合理的。
所以 沦为了 “纸面上的标准”。
至于 的编码规则这里就不做介绍了, 可以直接参考下文 。
GBK:
考虑到我国汉卡广泛应用的现状,我国相关部门推出了GBK标准,这一标准不仅兼容了原有内容,而且还额外增加了超过2万个字符位置。
它是怎么做到的呢?
GBK对编码范围进行了放宽,其高位字节现在扩展至0×81至0xFE,而低位字节则从0x40扩展至0xFE(不包括0x7F),这与另一种编码方式保持一致。
由此可见 GBK 是 的一个超集, 且和子集兼容良好。
:
这是我国目前最先进的内码字符集,与以GB开头的同类字符集相比sublime text 自动编码,其显著特征在于采用了可变长度的编码方式。
所谓的变长,即一个字符可能由1个、2个或4个字节构成,这与UTF系列编码方式相似。
它与 GBK , , ASCII 都是兼容的。
一个字节的数值区间为0至0x7F,且与ASCII编码相一致。
该字节的数值区间上限为0x81,下限为0x40,其高位数值介于0x81至0xFE之间,低位数值则与GBK编码标准相匹配,范围同样在0x40至0xFE之间。
该值的字节数不同,其范围也有所区别:单一字节时,其数值介于0x81至0xFE之间;当涉及两个字节时,其数值区间为0x30至0x39;若为三个字节,其数值同样在0x81至0xFE之间;至于四字节的情况,其数值范围则是从0x30延伸至0x39。
编码范围十分宽广,涵盖了亚洲绝大多数少数民族的文字。
在这GB家族的成员中,GBK格式则是依次被接纳并兼容的。
走向世界
上文提到的 GB 几兄弟虽然出色地解决了汉字的编码难题,然而它们却无法在国际舞台上施展,因为无论是 GB 还是 GBK,它们本质上都是“地区性双字节字符集”。这引发了一个相当棘手的问题,那就是同一份文本文件可能会因为编码集的差异,在国外计算机上根本无法被正确读取。
看来这个世界需要一个统一的字符集。
国际标准化组织(ISO)随即着手应对这一挑战,启动了名为“八位编码集合”(Octet Coded Set)的ISO 10646项目,简称UCS。在该方案中,组织决定摒弃所有地区性的双字节字符集(DBCS)方案,并努力将它们整合进一个统一的DBCS方案之中。
同时,由众多大型企业及组织共同维护的统一码联盟发布了统一码项目。
最初,UCS与该系统并不相容,然而这两个项目本意都是为了化解矛盾而设立,若各自为政,岂不是失去了设立两套系统的初衷?随后,两者实现了整合。现在,广泛使用的版本是UCS-2。
地方性的双字节字符集存在一个普遍的问题,即为了与ASCII兼容,0至127的编码范围不能用作高位字符。这一限制导致大量编码空间被闲置,为了充分利用这一空间,规定所有字符,包括ASCII字符,都必须使用两个字节来表示,从而显著增加了这种双字节字符集的容量。
按照这一规定,两个字节总共能够创造出六万五千三百六十六个可用位置。各个国家的字符系统各自占据了这六万多个位置中的特定区间。例如,希腊字母表占用了从某个起始代码到某个结束代码的范围,斯拉夫语则占据了从另一个起始代码到另一个结束代码的区间,美国字符集则使用从第三个起始代码到第三个结束代码的编码,而希伯来语则占用了从第四个起始代码到第四个结束代码的编码。至于中国、日本和韩国(统称为CJK)使用的编码,它们占据了从第五个起始代码到第五个结束代码的编码空间(看来我们占的比重还是相当大呢(⊙﹏⊙)b)。
这些摊位现在尚有部分空缺,通常情况下由FFF系列软件所占据,不过在不同类型的软件或操作系统上,这一情况可能会有所变化。
比如 这个字
(u3237) 在 Text 中会显示成
节约光荣,浪费可耻
尽管这解决了字符集统一的问题,然而代价也不小。在UCS编码下,每个字符都至少占用2个字节,有时甚至达到4个字节,即便是ASCII字符也不例外。这种编码方式导致了极大的资源浪费,尤其是在网络传输过程中。不信你走进联通营业厅看看,流量消耗多么惊人,那可都是真金白银啊。
为了攻克这一难题,科研人员确立了一种易于传播的编码模式——UTF(UCS),其中UTF还衍生出了UTF-8、UTF-16和UTF-32等版本。这些版本之间的区别在于,横杠后面的数字表示它们试图将单个字符压缩成多少比特。
例如,UTF-8编码尝试使用8个比特位来代表一个字符。
采用8比特(即1字节)来编码16比特(即2字节)的数据,必然会出现容量不足的问题,此时我们该如何应对呢?
– UTF8
十六进制二进制
0 007F
0 07FF
0 FFFF
0 FFFF
上图中的 x 为 UTF-8 的可编码范围。
它的转换规则如下:
若一个字节的首位为0,则该字节被认定为ASCII字节,除去首位外,剩余的7位即为ASCII码。因此,UTF-8编码与ASCII码具有兼容性。而当首个字节为1时,其后连续出现的“1”数量则指示了从该字符起,后续的字符共同构成一个完整的字位。 且后面的位置都要是用 10 开头的。
上图,上图,上图

UTF-16与前者相似,它试图使用两个字节来展现一个字符。在UTF-16编码体系中,若要表示UCS2字符,两个字节通常是足够的。因此,UTF-16主要应用于压缩UCS4字符。当两个字节无法满足需求时,它便会尝试使用更多的字节。其实现原理与UTF-8相近。
现在 下的 实现大多使用的都是 utf-16
汉字的窘境
截至目前,我们默认使用的是UCS2编码,而传输过程中采用的是UTF-8编码。对于ASCII字符,在UTF-8编码下其占用空间依然是1个字节。然而,汉字由于编码位置较后,使用UTF-8编码时往往需要3个或4个字节,这实际上使得其体积超过了原本的字节。
因此,针对含有较多ASCII字符的文章,UTF-8的压缩效果显著,通常能将文件大小减少至原来的一半左右。然而,对于含有大量汉字的文章,UTF-8的压缩效果却不如预期。
下的 ANSI
常见的一种编码被称为ANSI。然而,ANSI并不单纯是一种编码。它会依据操作系统所在的地域自动设定为相应地域的DBCS。例如,在简体中文环境下,ANSI实际上等同于GBK。通常情况下,ANSI会被默认使用。举例来说,当你创建一个记事本文件时,其中的文字默认就是以ANSI编码的。
u"我".("")
# b'\\u6211'
u"我".("gbk")
# b'\xce\xd2'
“我” 字的 是 62 11 GBK 下是 ce d2
我们来建一个记事本里,面写一个 “我”
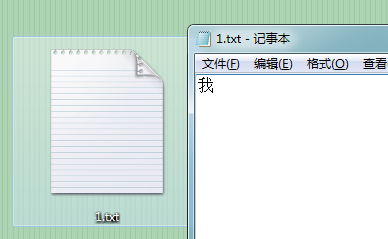
然后我们来查看他的字节码。

可以看到 ce d2 就是 “我” 的 GBK码。
锟斤拷锟斤拷烫烫烫烫。
有诗为证:
手持两把锟斤拷,口中疾呼烫烫烫。
脚踏千朵屯屯屯,笑看万物锘锘锘。
其中最出名的, 应该算是 “锟斤拷” 和 “烫” 了。
这些经典的乱码是怎么出现的呢?
首先来解释 “锟斤拷”
钅字旁透露着其质地,在中国古代,它被用作一种武器。提及往昔,女娲补天之际,太上老君……(突然,一声巨响!)

“锟斤拷” 主要出现在 GBK 和 混用的网页中。
在比较老的 web 服务器上是重灾区。
若要塑造“锟斤拷”,必须得有三位神仙齐心协力:那便是html文档,网络平台以及浏览器三者。
在制造过程中,首先,用户的HTML文件采用GBK编码,然而网页却错误地使用了另一种解码方式,导致解码结果出现异常。于是,将无法正确解码的字符统一替换为「U+FFFD」符号,接着将「U+FFFD」转换为UTF-8编码,最后再将处理后的数据发送给浏览器。
将「U+FFFD」编码转换为utf-8格式,得到的字符是 \xEF\xBF\xBD;若连续出现两个「U+FFFD」,转换后的结果将是 \xEF\xBF\xBD\xEF\xBF\xBD。
最终,当你用GBK编码来解析那些\xEF\xBF\xBD\xEF\xBF\xBD字符时,你便能够获得传说中的“锟斤拷”神器。
附一个 “锟斤拷”的例子
锟()
斤()
拷()
ps: 在此处,“U+FFFD”是一个特殊符号,它呈现为“�”。当系统在处理过程中遇到无法解释的字时,会采用“U+FFFD”来替代这些无法识别的字符。
下面说说 “烫”
“烫”这一现象主要在平台底层及ms的vc++编译器中频繁出现,特别是当你在栈内存中分配新的空间时,vc编译器会以0xcc作为初始化数据填充,连续的0xcc组合在一起,便形成了“烫烫烫烫烫”的视觉效果。同理,在堆内存中分配新空间时,则会采用0xcd进行填充,从而产生“屯屯屯屯屯屯”的效果。具体详情,请参考相关资料。
无论是“锟斤拷”还是“烫”,都必须确保最终输出的结果是GB码。
了解 与 , 的编码格式差异
原型中定义了一个内置函数,此函数能够输出指定位置上的十进制数值。
= "囧".(0);// 22247
= jiong.(16);// "56e7"
:
未经转换的字符涵盖了诸如星号、加号、减号、句号、逗号、斜杠、at符号、下划线、数字0至9以及小写和大写英文字母a至z等,这些字符将按照其原始形态被直接输出。
当系统遭遇非指定字符时,将输出相应的编码。以(囧)为例,其编码为“%u56E7”,这里的“56E7”代表字符“囧”的编码值。
:
不允许转换的字符涵盖了诸如感叹号、井号、美元符号、和号、单引号、括号、星号、加号、逗号、破折号、句号、分号、冒号、等于号、问号、、下划线、波浪号,以及数字0至9和大小写英文字母。
当遇到非上述指定字符时,系统会将其转换成对应的 UTF-8 编码。以“囧”为例,它会被转换成“%E5%9B%A7”,这里的“e5 9b a7”正是“囧”字符的 UTF-8 编码表示。此外,根据前面的说明,在 UTF-8 编码中,大多数汉字都会被转换成由三个字节组成的编码。
:
未经转换的字符涵盖了诸如感叹号、单引号、括号、星号、破折号、句点、下划线、波浪号以及数字0至9以及大小写英文字母a至z等。
同上它也是转换成 utf-8 编码格式。
国际上通用的网络传输格式为utf-8,尽管它并非W3C规范所定义的函数,但已被所有浏览器所支持并实现。
如有侵权请联系删除!

官方公众号
Copyright © 2023 江苏优软数字科技有限公司 All Rights Reserved.正版sublime text、Codejock、IntelliJ IDEA、sketch、Mestrenova、DNAstar服务提供商
Copyright © 2023 江苏优软数字科技有限公司 All Rights Reserved.正版sublime text、Codejock、IntelliJ IDEA、sketch、Mestrenova、DNAstar服务提供商
13262879759
微信二维码