
友好定价、专业客服支持、正版软件一站式服务提供
工作日:9:00-22:00

发布时间:2025-06-01
浏览次数:0
[id_[id_[]]]
part 1. SMC如何对抗静态分析
何为静态分析?
借助IDA Pro、Ninja等软件,我们通过执行反汇编、绘制控制流图以及识别字符串和函数等方式,对尚未运行的二进制文件进行深入分析。
何为动态调试?
运用GDB等调试工具,我们可以实时监控寄存器、内存以及代码的执行过程。
SMC是什么?
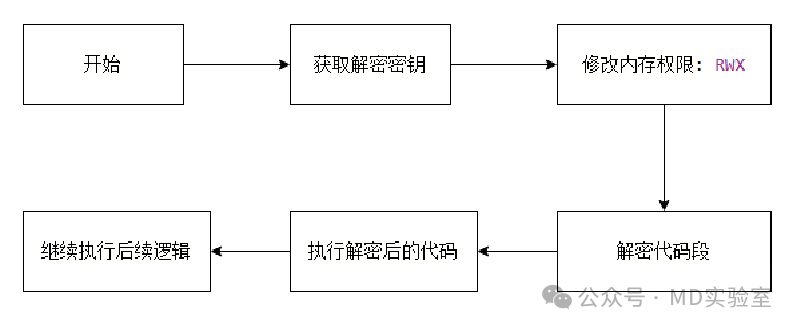
SMC(Self-Code)允许在代码执行前对其进行调整。因此,我们可以将代码以加密状态存储于可执行文件内,并在程序运行时进行实时解码。这样一来,在执行静态分析时,我们面对的将是加密后的数据,从而切断了静态调试的途径。
SMC有哪些应用场景?
防止调试/分析:关键代码在执行过程中进行加密处理,使得静态分析软件(例如IDA Pro)无法直接观察到其原始逻辑,从而提升了逆向工程的难度。
代码混淆:通过分段加密或动态生成代码,防止直接反编译。
许可证校验:关键校验逻辑仅在运行时解密,避免被绕过。
恶意软件规避检测手段:其病毒或木马的关键部分在内存中进行解密并执行,成功绕过了杀毒软件对静态特征的扫描。
游戏反作弊:关键检测代码动态解密,防止外挂篡改。
SMC的执行流程
part 2. 静态vs动态对比
静态分析
以 2020网鼎杯青龙组 .exe为例
为了直击核心内容,并且确保那些对逆向工程不太熟悉的人也能尽量理解,本文对程序的整个执行过程进行了简化分析,转而采用了程序执行流程图来展示。
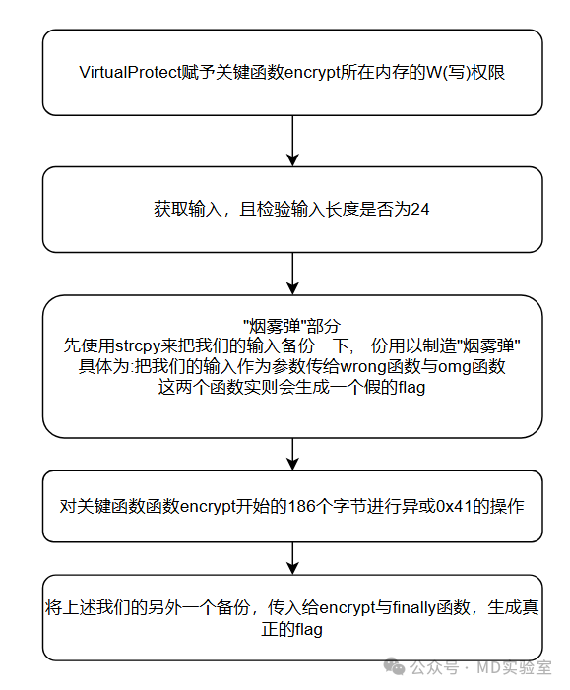
依据此流程图codejock software,与先前提到的SMC执行流程图进行对比,我们可以清晰看到,本程序的流程图中的
赋予关键函数所在内存的W(写)权限
对关键函数开始的186个字节进行异或0x41的操作
本程序展现出SMC程序的特点,故此,我们推测它很可能是一款SMC程序。基于这一推测,我们将对其展开进一步的检验。
双击函数,得到提示如下图所示
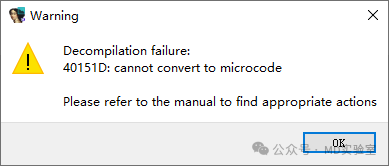
即反编译失败,那,不反编译,而是直接去查看该代码段试一下
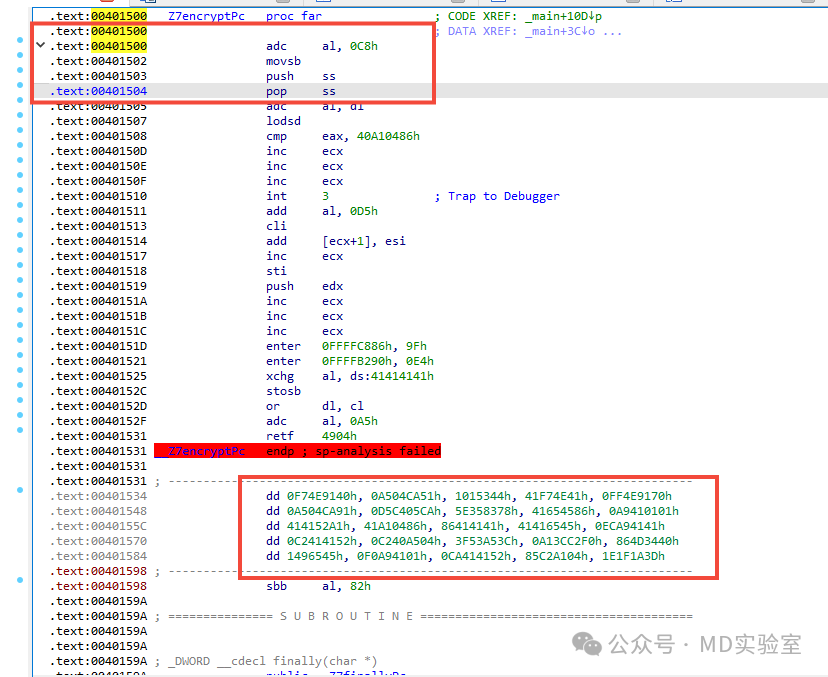
可以看到,这段代码有两点古怪之处:
该代码段缺乏一个标准的函数起始标记。标准的函数起始标记通常包括“push ebp”和“mov esp,ebp”这两条指令。然而,这段代码的起始部分却包含了无法理解的汇编指令。
下面出现了大量未进行反汇编的字节。
依据程序流程所揭示的信息,程序将对该代码段执行异或0x41的操作;同时,由于反编译后无法正常运行,以及直接审视代码段codejock software,我发现了两个异常点;据此,我可以断定这涉及了SMC保护机制,且加密解密密钥设定为0x41,受保护的函数区域起始于186个字节。
动态运行
根据上述推论,在完成SMC解密操作之后,我们能够在此环节处设置断点,继续执行。
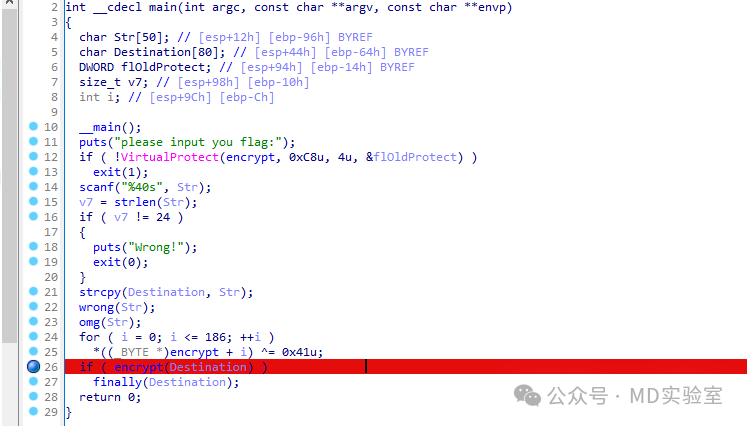
为了确保我们的输入达到指定的长度标准,即24个字符,我们必须生成一个长度恰好为24的任意字符序列。
这里选择24个'a'
程序成功断下
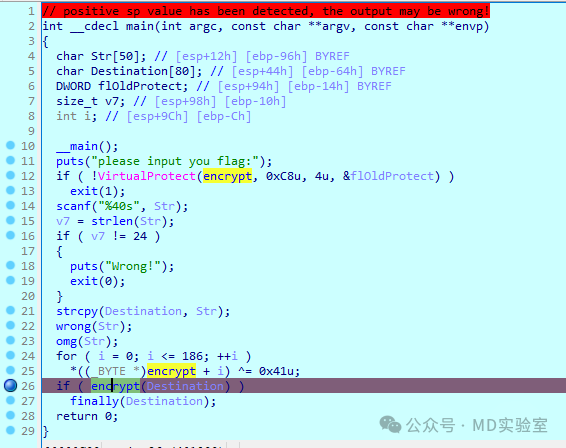
然后双击函数,可以看到已经出现了正常的函数头了
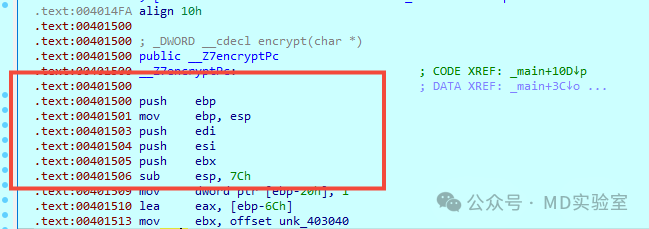
尽管如此,IDA仍然未能对该代码区域进行精确的识别,其中仍有部分字节未被识别出来,而且该代码段并未被正确地识别为函数。
为了解决这个问题,开始第三章:如何绕过SMC
part 3. 如何绕过SMC
借助
经过前期的分析,我们了解到该程序采用了SMC技术,其加解密密钥标识为0x41,且加解密操作覆盖了从起始位置起的186个字节。
基于此,我们可以借助进行手动解密。
具体代码为:
for i in range(0x401500,0x401500+186):
在处理第i个字节时,需将其与通过get_wide_byte(i)函数获取的宽字节进行位运算,并执行位异或操作。0x41)
尽管运行这段代码能够实现手动解密,但IDA在识别过程中却表现不佳,常常会出现如下的情形,即普通字节与汇编指令交织在一起的情况。
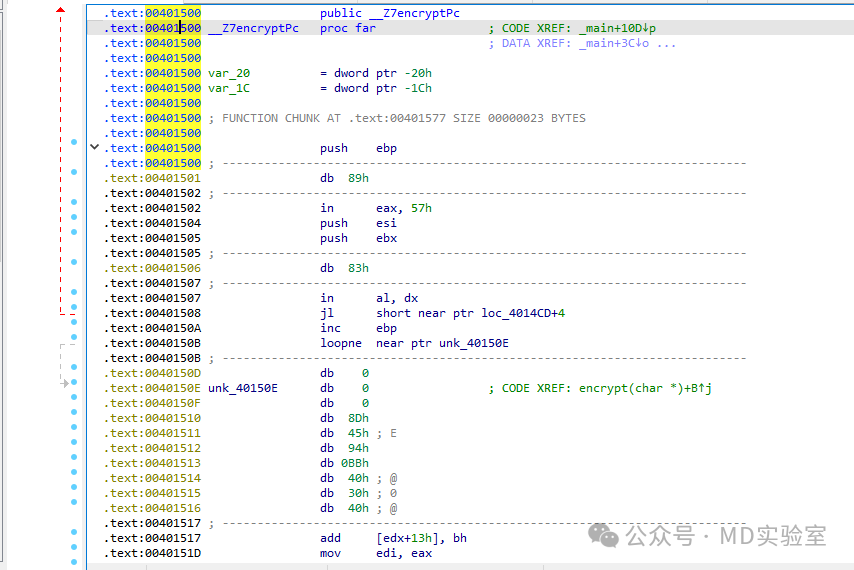
为了确保IDA能够准确识别,我们能够持续利用此方法,将内容强制转换为常规字节序列,随后人工指导IDA将该字节序列识别为代码,最终将其归类为函数。
我们运行如下代码:
for i in range(0x401500,0x401500+186):
ida_bytes.del_items(i,0,1)
得到结果如下图所示
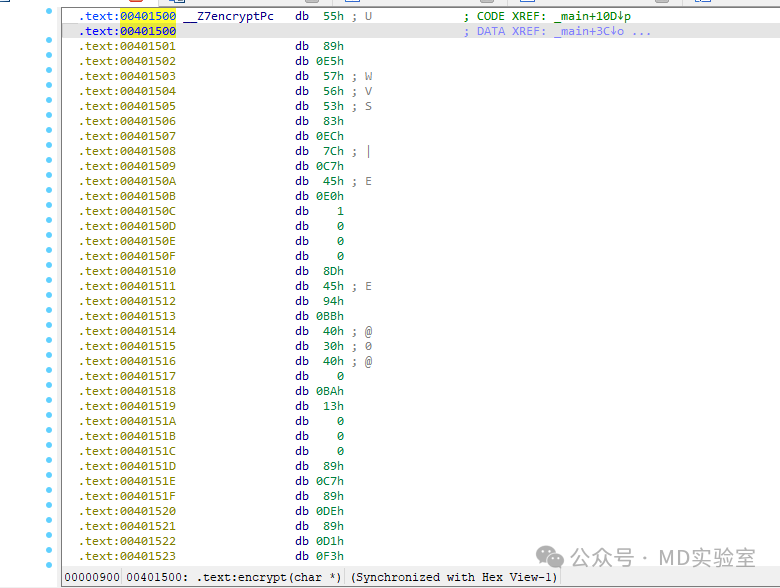
可以看到这一段代码全部被视为了普通字节。
接下来在函数头,也就是的位置按下快捷键C
得到结果如下图所示
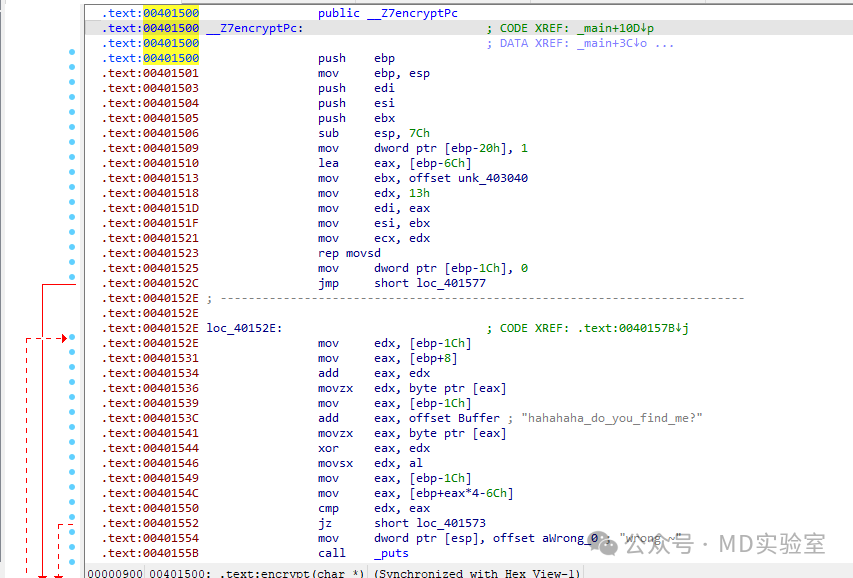
然而,我们能够清晰观察到,前方的.text:部分依旧呈现红色,这表明该段内容尚未被准确识别为函数。请继续在函数的起始位置,也就是函数头所在的位置,按下一个快捷键P。
得到结果如下图所示
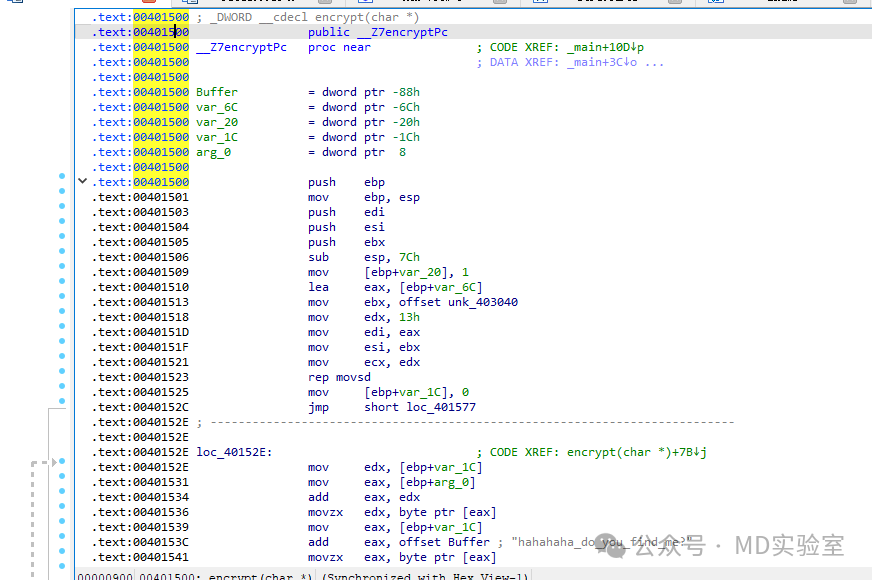
显而易见,此次IDA已准确将其识别为函数,如此一来,我们便成功实现了对SMC的规避。
后续的其他逻辑也可以借助IDA进行静态分析了。
part 4. 如何实现自己的SMC程序
为了更直观,首先给出一个流程图
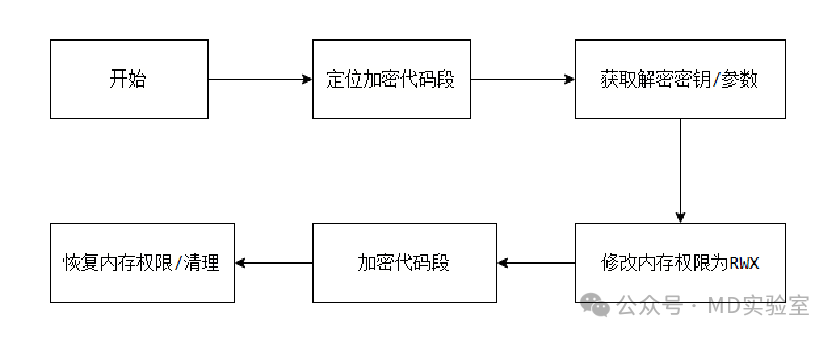
这里需要解决几个问题:
如何定位加解密代码段?
如何加密代码段?
解决问题1
针对问题1,其相当于两个小问题:
如何确定加解密代码段的起始地址?
如何确定加解密代码段的长度?
为了样例足够简单,我们设计了一个需要保护的函数Fun1()
为了准确找出加密与解密代码段的起始位置,在编写过程中,我们将其放置于一个特定的段,即段名为.hello的区域。
#pragma code_seg(".hello")
int Fun1()
{
int a = 1;
int b = 3;
return a + b;
}
void Fun1end() {}
#pragma code_seg()
#pragma comment(linker, "/SECTION:.hello,ERW")
那么.hello段的起始地址即为Fun1()的起始地址
设计一个空函数体()的目的,同样是为了能够通过(BYTE*)与(BYTE*)Fun1之间的差值,来计算受保护代码段的实际长度。
解决问题2
首先我们需要确定整个函数体的运行流程
确定加解密密钥
|
|
↓
对受保护的函数进行解密(异或上加解密密钥)
|
|
↓
执行受保护的函数
基于此流程,得到CPP文件的main函数为
int main() {
printf("Fun1 address: %p\n", Fun1);
printf("Fun1end address: %p\n", Fun1end);
printf("Calculated size: %d\n"Fun1end 减去 Fun1 等于 (BYTE*) 的差值。
char key[2] = { 0x66 };
UnPack(key);
int ret = Fun1();
printf("ret = %d\n", ret);
getchar();
return 0;
}
接下来可以借助外部工具如脚本对其进行主动加密:
之所以必须采取主动加密措施,是因为在将我们的CPP文件转换成exe文件后,Fun1()函数并未得到保护。此外,程序运行时首先执行的是对数据进行异或0x66的操作,这一步骤实际上起到了加密Fun1()的作用,进而可能导致程序崩溃并无法正常运行。
对其主动进行加密处理后,Fun1()便处于了受保护的状态,唯有如此,程序中针对0x66的异或操作才能有效作用于已受保护的Fun1。借助异或运算的对称特性,Fun1得以恢复其原始形态。
基于此思路,我们设计了如下脚本(main函数部分)
if __name__ == "__main__":
filename = "样例(无SMC).exe"# 原始文件
section_name = ".hello"# 目标区段
xor_key = 0x66# 异或密钥
code_size = 0x20# 替换为实际值,即上述exe运行以后输出的值
print(f"[*] Loading {filename}")
创建PE文件对象,名为pe_file,通过使用pefile库,并传入文件名filename。
print("[*] Encrypting section")
if对指定文件中的特定部分进行加密,使用异或密钥,并设定编码大小,操作函数名为encrypt_section,参数依次为pe_file(文件对象)、section_name(段名称)、xor_key(异或密钥)和code_size(编码大小)。
将原文件名中的后缀替换为新的后缀,并保存为新的文件名。-4] + "_optimized.exe"
print(f"[*] Saving as {new_filename}")
将新文件名写入pe文件中。
else:
print("[!] Encryption failed")
pe_file.close()
经过这一阶段,我们成功自主开发了SMC程序。这也就意味着,今天的讲解即将落下帷幕。
完整CPP文件和文件
CPP文件如下:
#include
#include
#include
usingnamespacestd;
#include
#pragma code_seg(".hello")
int Fun1()
{
int a = 1;
int b = 3;
return a + b;
}
void Fun1end() {}
#pragma code_seg()
#pragma comment(linker, "/SECTION:.hello,ERW")
void xxor(char* soure, int dLen, char* Key, int Klen) //异或
{
for (int i = 0; i < dLen;)
{
for (int j = 0; (j < Klen) && (i < dLen); j++, i++)
{
源数组中的第i个元素与密钥数组中的第j个元素进行异或运算,结果赋值给源数组中的第i个元素。
}
}
}
void SMC(char* pBuf, char* key) //SMC解密/加密函数
{
constchar* szSecName = ".hello";
short nSec;
定义一个指向DOS头部信息的指针,名为pDosHeader。
定义一个指向PIMAGE_NT_HEADERS结构的指针,名为pNtHeader。
定义一个指向PIMAGE_SECTION_HEADER类型的指针,命名为pSec;
pBuf指向的内存区域被转换为PIMAGE_DOS_HEADER类型,并赋值给变量pDosHeader。
pNtHeader指向的地址是pBuf中从pDosHeader的e_lfanew偏移量处开始的PIMAGE_NT_HEADERS结构体。
nSec 等于 pNtHeader 指针指向的文件头结构中的节数量;
pSec 等于 PIMAGE_SECTION_HEADER 的地址,该地址指向 pBuf 数组中的相应位置。sizeofIMAGE_NT_HEADERS结构体与pDosHeader指向的e_lfanew偏移量相加。
for (int i = 0; i < nSec; i++)
{
if (strcmp((char*)&pSec->Name, szSecName) == 0)
{
int pack_size;
char* packStart;
pack_size 等于 pSec 指针指向的结构的原始数据大小。
pack_size 等于 Fun1end 指针指向的地址与 Fun1 指针指向的地址之间的差值,该差值以 BYTE 类型表示。
输出:Fun1end的值是十六进制形式,显示为%x,Fun1的值同样以十六进制形式呈现,具体为%x,而pack_size的值则是%d。
packStart指向pBuf数组中,由pSec的虚拟地址确定的起始位置。
对packStart、pack_size、key以及相关参数进行限制,确保它们在特定范围内有效。strlen(key));
return;
}
pSec++;
}
}
void UnPack(char* Key) //解密/加密函数
{
char* hMod;
hMod = (char*)GetModuleHandle(0); //获得当前的exe模块地址
SMC(hMod, Key);
}
int main() {
printf("Fun1 address: %p\n", Fun1);
printf("Fun1end address: %p\n", Fun1end);
printf("Calculated size: %d\n", (BYTE*)Fun1end - (BYTE*)Fun1);
char key[2] = { 0x66 };
UnPack(key);
int ret = Fun1();
printf("ret = %d\n", ret);
getchar();
return0;
}
文件如下:
# -*- coding: UTF-8 -*-
import pefile
def encrypt_section对文件进行操作时,需指定文件名、章节名称、异或密钥,若未指定代码大小,则默认为无限制。:
"""加密PE文件中指定的区段"""
for section in pe_file.sections:
if section.Name.decode().strip('\x00') == section_name:
print(f"[*] Found {section_name} section at 0x{section.PointerToRawData:08x}")
获取数据,操作如下:section对象调用get_data方法,并将结果赋值给变量data。
# 如果指定了代码大小,只加密有效部分
加密数据的大小等于编码数据的大小。if code_size else len(data)
加密长度应限制为加密大小与数据长度中的较小值。# 确保不越界
print(f"[*] Encrypting {encrypt_size}/{len(data)} bytes")
# 仅加密有效代码部分
加密后的数据等于字节序列,该序列由每个数据元素与异或密钥进行异或操作的结果组成,这些结果位于索引i的位置。for i in range(encrypt_size)])
# 保留后面的原始数据
最终数据等于加密数据加上数据中从加密大小之后的部分。
pe_file在section的PointerToRawData偏移处设置了final_data字节。
print(f"[*] Successfully encrypted {encrypt_size} bytes")
returnTrue
print(f"[!] Section {section_name} not found!")
returnFalse
if __name__ == "__main__":
filename = "样例(无SMC).exe"# 原始文件
section_name = ".hello"# 目标区段
xor_key = 0x66# 异或密钥
# 通过逆向分析或调试获取实际代码长度
code_size = 0x20# 替换为实际值
print(f"[*] Loading {filename}")
pe_file = pefile.PE(filename)
print("[*] Encrypting section")
if encrypt_section(pe_file, section_name, xor_key, code_size):
new_filename = filename[:-4] + "_optimized.exe"
print(f"[*] Saving as {new_filename}")
pe_file.write(new_filename)
else:
print("[!] Encryption failed")
pe_file.close()
如有侵权请联系删除!

官方公众号
Copyright © 2023 江苏优软数字科技有限公司 All Rights Reserved.正版sublime text、Codejock、IntelliJ IDEA、sketch、Mestrenova、DNAstar服务提供商
Copyright © 2023 江苏优软数字科技有限公司 All Rights Reserved.正版sublime text、Codejock、IntelliJ IDEA、sketch、Mestrenova、DNAstar服务提供商
13262879759
微信二维码