
友好定价、专业客服支持、正版软件一站式服务提供
工作日:9:00-22:00

发布时间:2024-09-14
浏览次数:0

第一名
背景
2017年,一篇题为Code from a User的论文引起了业界的关注,论文中描述了利用深度学习技术从UI截图中识别并生成UI结构描述,再将UI结构描述转化为HTML代码。有人认为这种从UI截图生成UI结构描述的方法不可行,直接从截图生成代码意义不大,AI与软件本来就是用数据结构来存储设计文件的结构描述,并不需要通过机器学习来获取,且生成的代码不确定性较大。也有人肯定这种想法,提出让深度学习模型学习UI界面特征,进行UI智能设计。
随后,基于开发的项目进入了排行榜的第一位,这款工具可以自动将UI截图转换成HTML代码,项目作者宣称人工智能将在三年内彻底改变前端开发,不少用户也对此表示质疑,认为前端技术复杂,框架各异,单靠HTML代码无法满足需求。
2018年,微软AI实验室开源了-to-code工具,有人认为其生成的代码不够理想,不适合用于生产环境,但也有人认为自动代码生成尚处于早期阶段,其未来的发展值得想象。
2019年,阿里巴巴开放智能代码生成平台,通过识别设计稿(/PSD/图片)可以智能生成React、Vue、小程序等不同类型的代码,同年自动生成了79.34%的前端代码,智能代码生成不再只是线下实验产品,而是真正创造了价值。
每当这些新的自动代码生成产品发布时,网上总会掀起“人工智能会取代前端吗”、“大量前端程序员将失业”之类的讨论。
人工智能会取代前端吗?人工智能在未来很长一段时间内都不会取代前端,但是会改变前端,首先会改变前端探索者们在前端智能化方向上的探索,除了成为服务之外,首先前端工程师可以成为机器学习工程师,为前端智能化领域创造更多的价值和成果;其次会改变享受前端智能化成果的前端开发者们,改变他们的研发方式,比如代码智能生成、代码智能推荐、代码智能修正、UI自动化测试等都可以帮助他们完成大量简单重复的工作,让他们把更多的时间花在更有价值的事情上。
本文将与大家分享我们作为前端智能领域的探索者,如何看待人工智能在前端领域的未来发展方向,以及如何在智能代码生成平台上推动智能能力的应用和迭代升级,助力今年双11会场新增模块90.4%的代码实现智能生成,编码效率提升68%。
2号
中期业绩
官网首页月均PV为6519,月均UV为3059,相较于2019年,2020年的月均PV和UV均为2019年的2.5倍。
用户数18305个,其中77%为社区用户,23%为阿里巴巴集团内部用户。模块数56406个,其中68%为外部模块,32%为内部模块。与2019年之前的总数相比,2020年用户数增长了2.7倍,模块数增长了2.1倍。
社区覆盖集团内至少150家公司、10个以上BU,双11现场新增模块覆盖率90.4%,智能生成代码留存发布比例79.26%,编码效率(模块复杂度与研发开发时间比)提升68%。
相比2019年,用户感知效率提升了14%;相比完全不使用D2C,固定人力单位时间模块所需吞吐量提升约1.5倍;相比传统研发模式,研发链路编码效率可提升约68%。
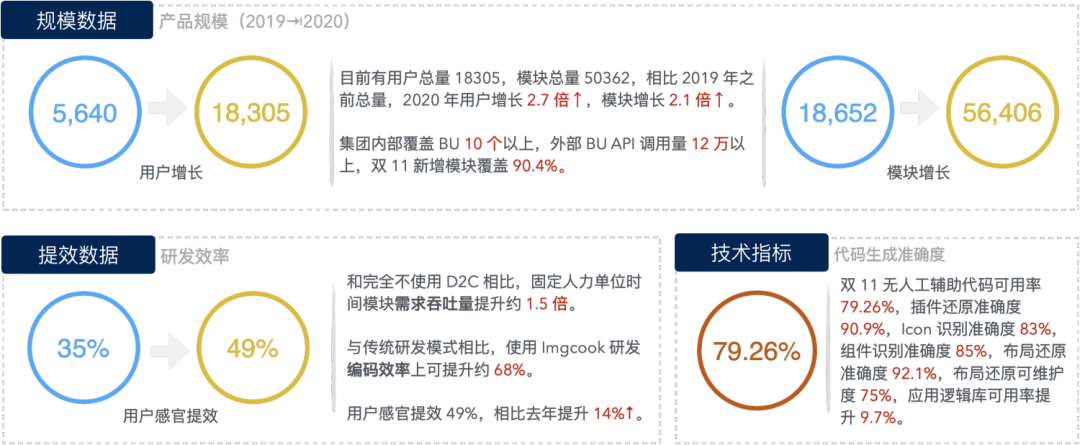
(研发绩效数据概览)
NO.3
技术产品体系升级
技术原理介绍
我们先来了解一下智能代码生成的原理,自动代码生成主要做两件事:从可视化草稿中识别信息,然后将这些信息表达成代码。
本质是通过设计工具插件从设计稿中提取 JSON 描述信息,通过规则系统、计算机视觉、机器学习等智能还原技术对 JSON 进行处理和转换,最终得到符合代码结构和代码语义的 JSON,然后使用 DSL 转换器,转换为前端代码。DSL 转换器是一个 JS 函数,输入是一个 JSON,输出就是我们需要的代码。例如 React DSL 的输出就是符合 React 开发规范的 React 代码。

(利用动态线的D2C智能代码生成)
最核心的部分是 JSON to JSON,设计稿中只包含图片、文字等元信息,位置信息为绝对坐标,设计稿中的样式和网页中的样式也有区别,比如透明度属性不会影响 Child 节点,但在网页中会影响 Child 节点,并且手工编写的代码有各种布局类型,DOM 结构需要合理可维护,代码需要语义化、组件化、循环化等信息。
如何像手工写代码一样智能地生成代码,是智能还原部分要解决的问题。我们将D2C智能还原部分分成了层层递进,每层的输入输出都是JSON,层层进行JSON的转换,这就是智能还原的整个流程。如果需要修改生成的JSON,可以通过编辑器进行可视化的干预,最终通过DSL开放层将得到的符合代码结构和语义的JSON转换为代码。
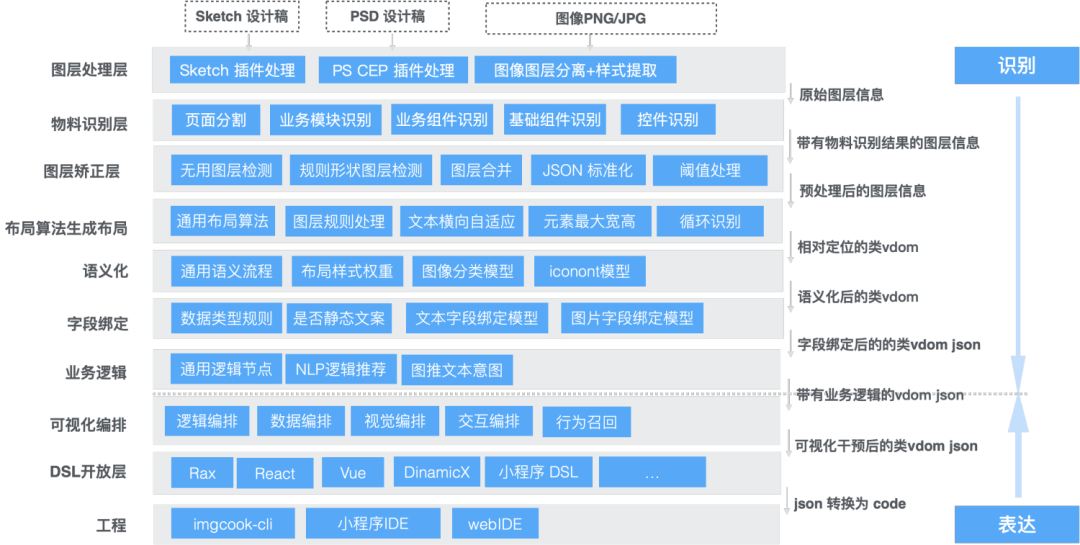
(D2C智能修复技术分层)
智能还原核心环节构成了D2C的核心技术体系,并通过衡量体系衡量核心还原能力与研发效率提升效果。下层依托算法工程体系,提供核心技术体系中智能化能力的底层服务,包括样品制造、算法工程服务以及前端算法工程框架等。上层通过D2C研发体系承接智能还原后端环节,通过提供可视化干预能力满足用户二次迭代的需求,通过将工程环节构建到平台中,实现一站式开发、调试、预览和发布,提升整体工程效率。加上支持自定义DSL、自定义开发素材等高扩展定制能力形成的开放体系,形成了整个D2C架构,服务于阿里巴巴内部C端、小程序、中后台以及外部社区等各类业务场景。
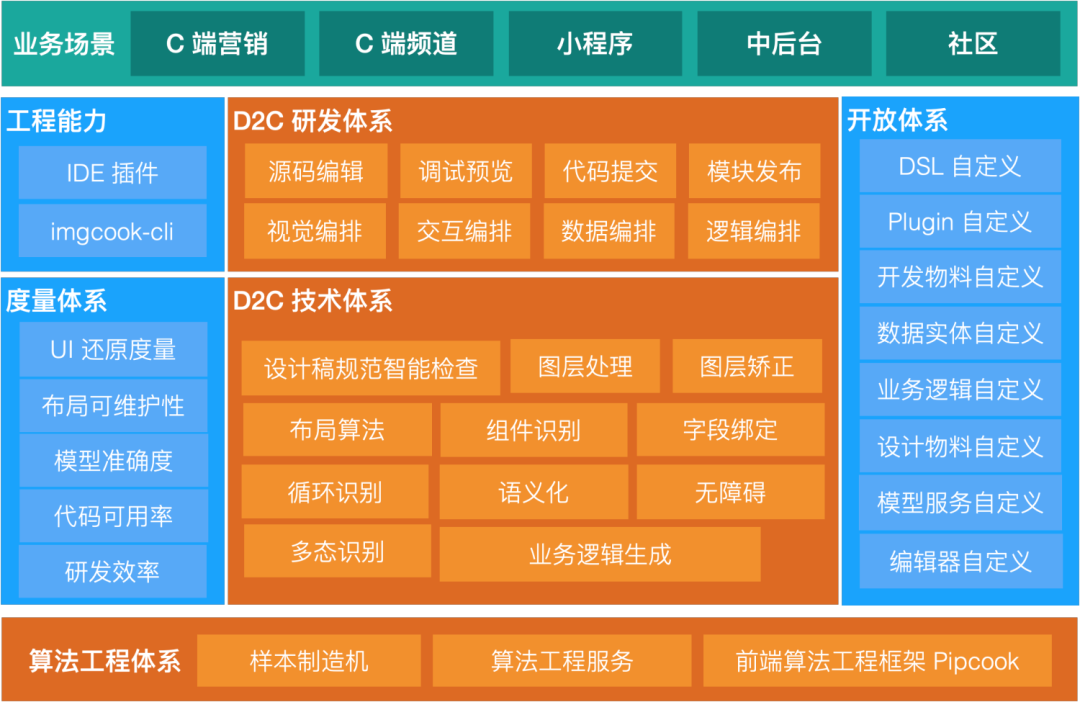
(D2C技术架构图)
今年在前端智能化的背景下,我们对整个D2C技术体系的智能化能力进行了升级,为前端同学们提供了前端算法工程框架,让前端工程师成为解决样本采集问题的机器学习工程师、样本制造机器。同时也带来营销模块研发链条上的产品升级,助力提升整个链条的研发效率。
智能能力升级
智能能力层定义
《汽车驾驶自动化分级标准》以驾驶自动化系统执行动态驾驶任务的程度为标准,按照执行动态驾驶任务时的角色分配、是否存在设计工况限制等,将驾驶自动化分为0~5级。在自动驾驶中,驾驶员的角色转变为乘客。这一明确的标准将有助于各类企业更有针对性地开展研发和技术布局。

(自动驾驶分级标准)
参考自动驾驶分级标准,我们根据D2C系统自动生成代码的程度,按照代码的作用以及是否需要人工干预和验证,定义了D2C系统交付的分级标准,以帮助我们了解D2C系统目前的水平以及下一阶段的发展方向。
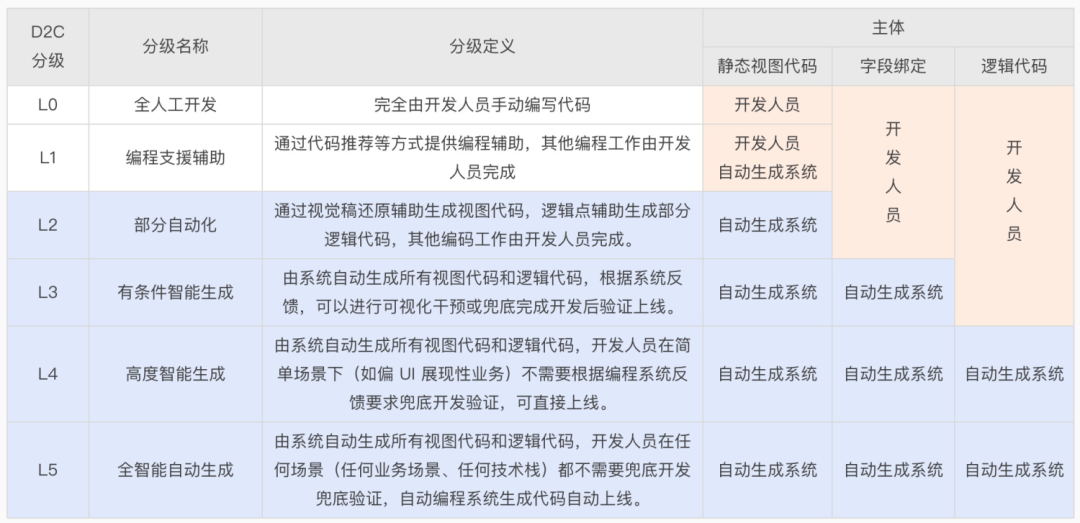
(D2C系统配送分类参考标准)
目前的能力是D2C的L3级别,智能生成的代码在开发完成后还是需要视觉干预或者人工验证,未来我们希望达到L4级别,需要拆解UI信息架构,从UI信息自动生成代码,能力是分段的。
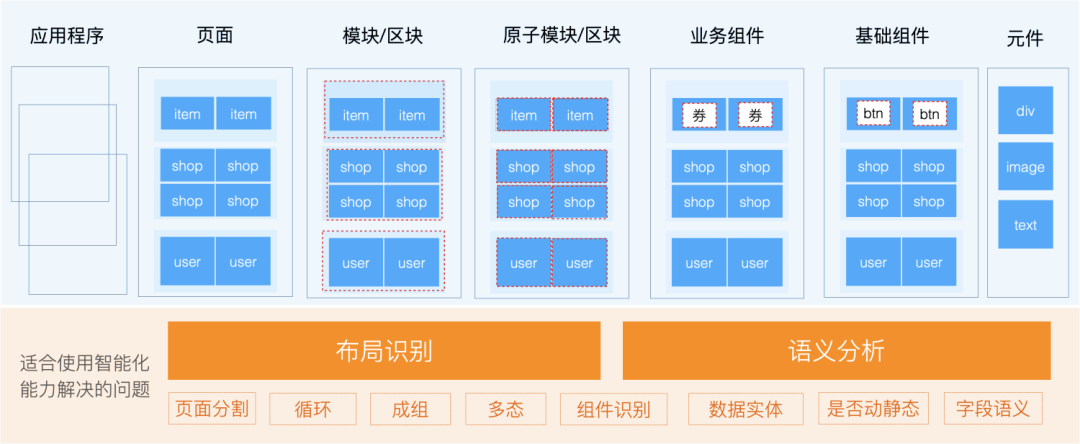
(UI信息架构解构)
一个应用由多个页面组成,每个页面按照UI粒度可分为模块/块、原子模块/块、组件(业务组件、基础组件)、元素等,需要识别其布局结构和语义,才能生成模块化、组件化、语义化、类似手工编写代码、可维护性强的代码。
在分析UI信息架构的基础上,我们利用代码生成的技术体系,将不同粒度的智能能力划分为I0-I5(I为英文字母首字母)。
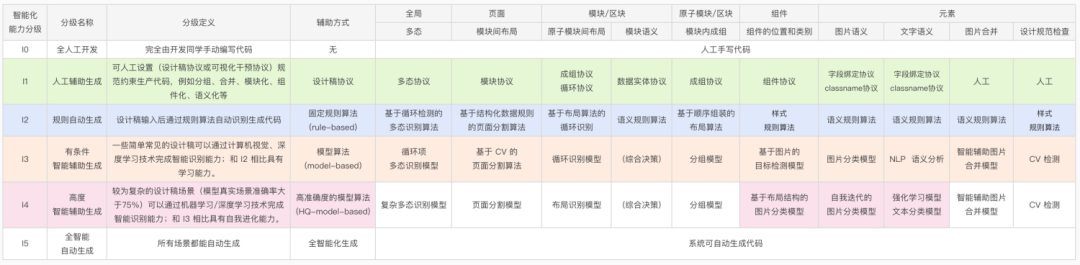
(D2C智能能力分级)
着色部分是目前已经具备的能力,从这个角度来看,智能化能力目前处于I3、I4级别,在生产环境中和I2级别能力协同工作。I3级别的智能化能力需要不断优化和完善,对模型进行迭代,当线上真实场景准确率达到75%以上或者模型具备自迭代能力时,就进入I4级别。如果达到I5级别的智能化能力,按照D2C系统交付分级参考标准,D2C系统交付分级可以从L3提升到L4。进入L4之后,生成的代码可以直接上线,不需要人工干预和验证。
当然我们可能还处于L4级别sketch导入ai,人机协同编程的阶段,这个分类的定义是为了推动智能化落地的进程,可以指导我们提升D2C智能化能力,对D2C智能化有更清晰的认识。
我们以生成代码的可用性作为总体技术指标,并按照代码生成环节的技术分层,给出各个阶段的技术指标及对代码可用性的影响权重。 生成代码理论准确率=(各环节准确率)+实际代码可用率=生成代码在最终上线代码中保留的百分比。
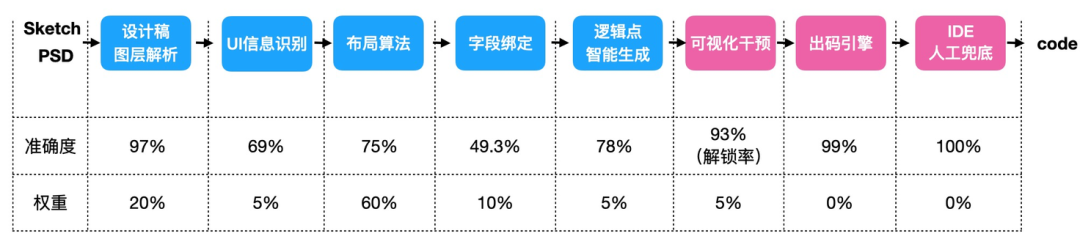
(各层技术指标及权重定义)
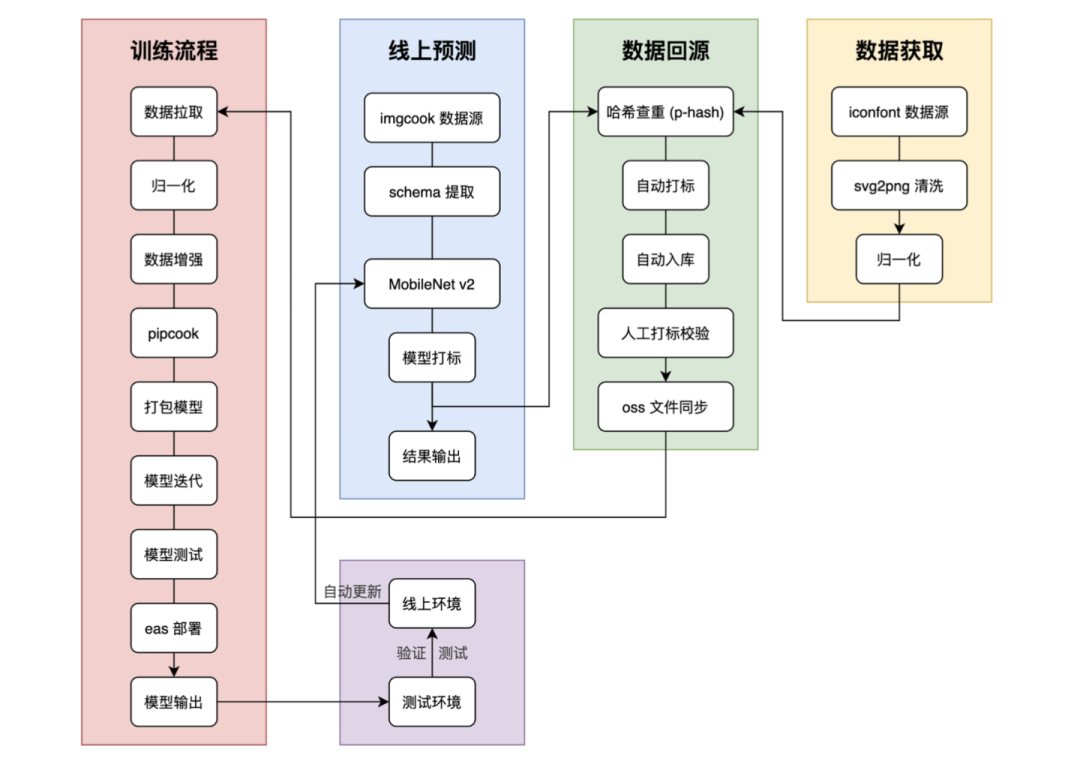
D2C的智能能力分布在修复链路的各个阶段,我们以提高代码可用性为目标,对整个链路的智能能力进行升级,细化技术方案,提升每个阶段模型的识别准确率,以及如何将识别结果最终应用到智能修复链路生成代码。如何让从样本采集、模型训练、模型部署到模型应用到工程化链路的整个流程实现自动化、自我迭代优化,不断优化迭代模型能力。
智能化能力的应用还需要模型识别结果的应用、在线用户行为召回、前端开发组件对UI组件识别结果的接受等工程化环节的支持,整体D2C技术体系也需要同步升级。
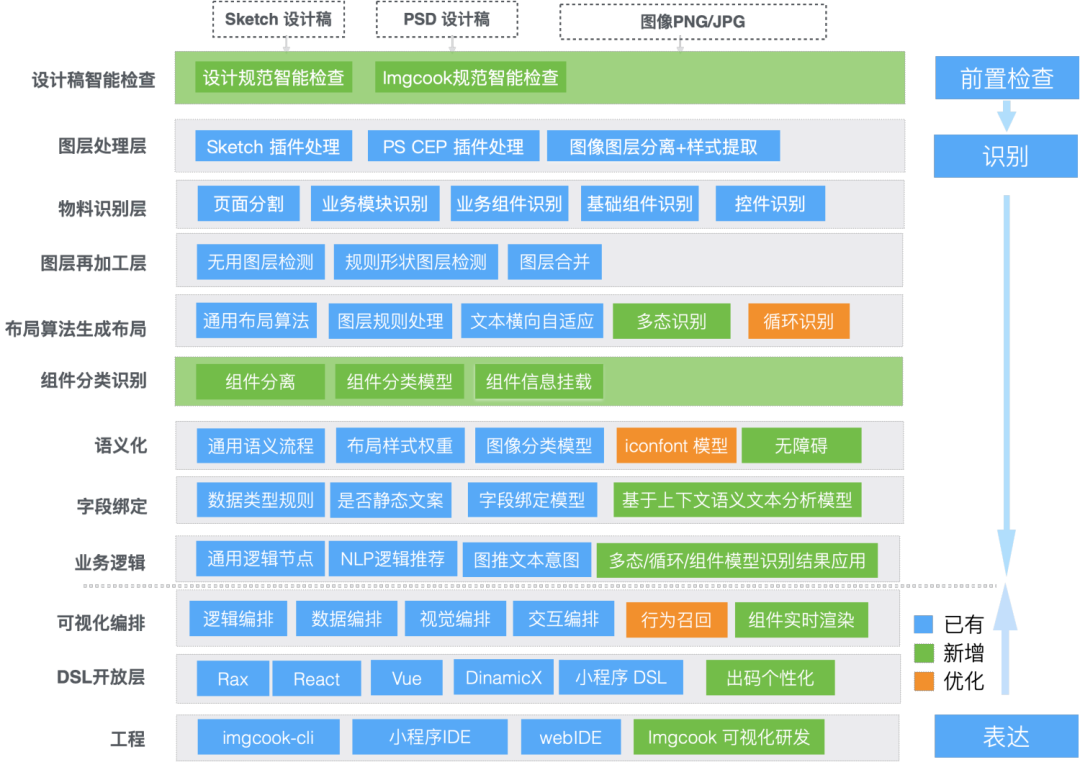
(D2C技术系统升级图片)
各阶段智能能力升级 层层分析阶段
通过解析设计稿图层信息,通过规则体系和智能技术进行识别并生成代码,由于设计域与研发域在表达、结构、规范等方面存在差异,设计稿的图层结构对生成代码的合理性影响比较大,而且一些设计方式不规范的设计稿需要利用“分组”和“图片合并”协议对设计稿进行调整。
开发者在开发代码时,经常会遇到写不必要的.log、没有注释、变量重复声明等问题,为了解决这些问题,提供了 和 等工具来保证代码标准的统一性。
在设计领域,我们还可以开发一套智能的设计稿规范检查工具,保证设计规范,智能审核设计稿的规范性,提示错误并协助调整。我们把这套工具叫做 Lint(DLint)

(设计规范检查)
材料识别阶段
UI素材可以分为模块/块、组件、元素,PSD直接提取出来的信息只有文字、图片和位置信息sketch导入ai,直接生成的代码由div、img、span组成,代码语义至关重要,如何从设计稿中提取组件和语义信息,是NLP、深度学习等智能技术非常适合解决的问题。
去年我们在部件识别、图像识别、文本识别等方面进行了探索和实践,识别结果最终还是要用于语义和字段绑定,但所采用的技术方案对识别效果有很大的限制,今年我们做了以下改进:
组件识别
原本使用目标检测方案来识别UI组件,但该方案需要同时识别正确的组件类别和正确的位置,需要整幅视觉图像作为输入,复杂的图像背景容易误识别,识别的位置偏差导致难以贴装到正确的节点,在线应用中模型识别结果准确率较低。
基于这些原因,以及能够从视觉草图中获取各层位置信息的优势,我们将解决方案转化为图像分类,并能够将识别结果应用到现实网络世界中。这是依靠一组可配置的组件实现的。一个可以识别、渲染、干预和编码的智能材料系统。
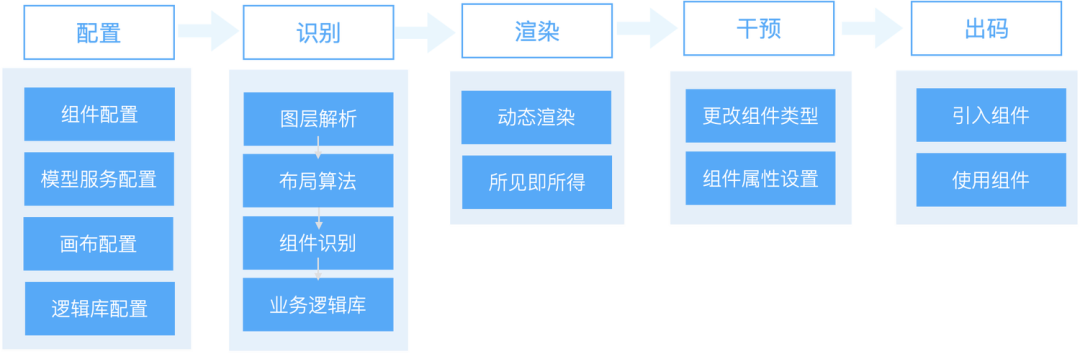
(元件识别应用完整链接)
下面进行线上应用组件识别的演示,识别可视化稿中的视频信息,并使用 rax-video 前端组件生成组件级代码。需要配置自定义组件(组件库设置)、组件识别模型服务(模型服务设置)、支持渲染视频组件的画布资源(编辑器配置-画布资源)、应用组件识别结果的业务逻辑点(业务逻辑库配置)。
(元器件识别全链路演示)
图标识别
图标识别其实就是图像分类的问题,我们还是沿用图像分类的解决方案,但为了增强模型的泛化能力,我们设计了图标模型,从自动采集、处理数据、训练模型、发布模型,形成闭环环节,让模型自我迭代、自我优化。
(图标识别模型闭环链接)
自上线以来,新增训练集总数已达2729个,平均每月检索有效数据909条,经过多次自我迭代,模型测试集准确率由80%提升至83%。
图像/文本语义识别
智能系统的一个关键部分是如何将语义信息绑定到UI界面中的元素上,之前的解决方案是基于图像和文本分类的模型识别,这种识别方式存在很大的局限性:只对文本进行识别,没有考虑整个UI界面的上下文语义进行分类,导致模型性能不佳。
例如$200无法通过文本分类进行语义识别,因为它在不同的场景下具有不同的含义,比如促销价、原价、折扣券等,正确的做法是考虑该字段基于其与UI界面的关联性(即独特的风格)进行语义分析。
因此我们引入了可以结合UI中的上下文语义进行语义识别的解决方案。我们采用了图元决策+文本分类的两步方案来解决界面元素语义化的问题。具体流程是:首先我们基于强化学习对界面元素进行分类,通过样式进行“过滤”,识别出有样式的非纯文本字段,再对纯文本字段进行分类。具体框架如下。
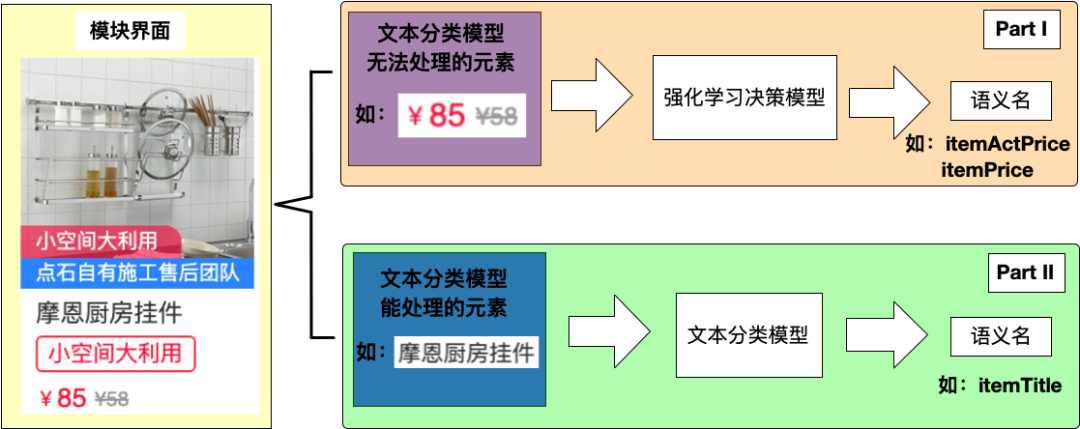
(强化学习+文本分类)
以下为模型算法训练结果
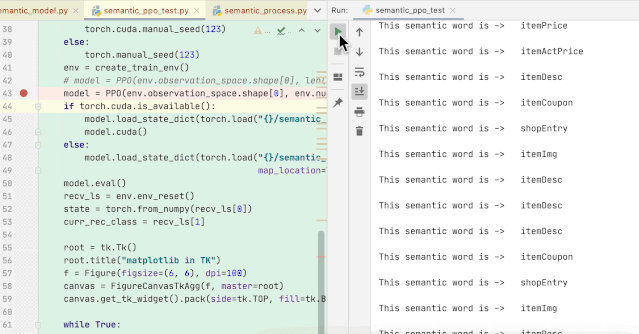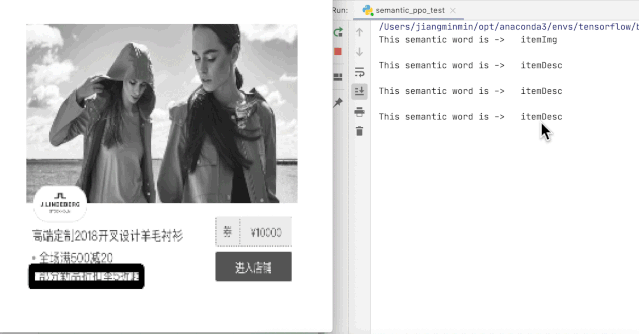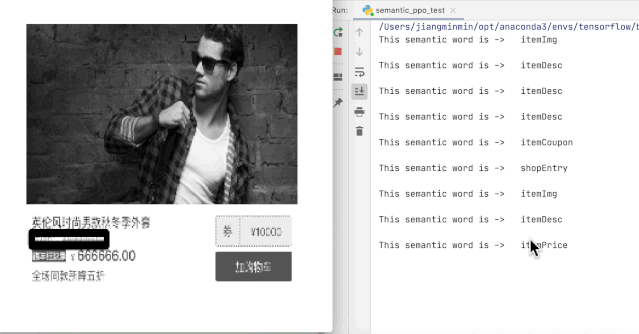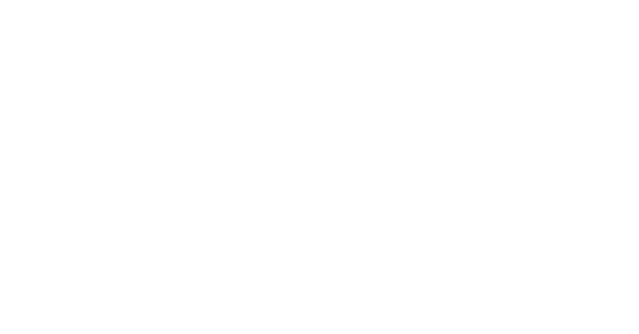
(根据上下文进行语义分析)
布局恢复阶段
布局就是代码中各个节点之间的关系,是父子关系还是兄弟关系,从粒度上看,可以分为页面之间的模块/块之间的关系,模块/块内原子模块/块之间的关系,代码中节点之间的块之间的关系以及原子模块/块内组件、元素之间的关系。
目前已经具备了循环和多态的识别能力,可以识别设计稿中的循环体并生成循环代码,也可以识别同一节点的多种UI状态并生成多状态的UI代码,同时还定义了布局可维护性度量方法,以衡量修复阶段的准确性。
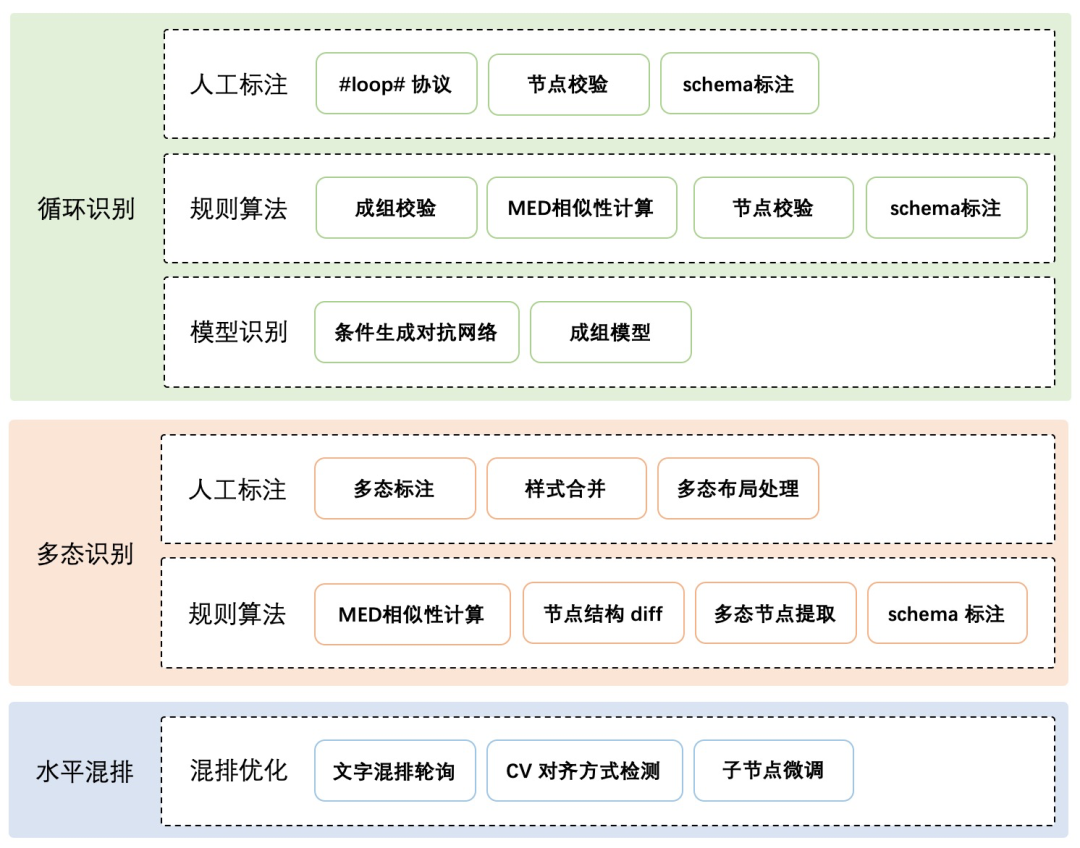
(布局恢复阶段的识别能力升级)
逻辑生成阶段
在业务逻辑生成阶段,优化原有的配置环节,将业务逻辑库与算法工程环节解耦,将识别结果全部应用和表达出来。素材识别阶段,只关注UI中的素材,不关注识别出来的素材。结果如何生成代码,和布局还原阶段的循环识别、多态识别是一样的。这样做的好处是,我们可以自定义识别结果的表达方式,让用户感知智能识别的结果,选择是否使用。
除了从业务逻辑库中生成逻辑代码之外,还可以从需求稿中,或者从代码片段推荐中,或者从代码智能推荐(Code to Code,C2C)中生成一些逻辑。
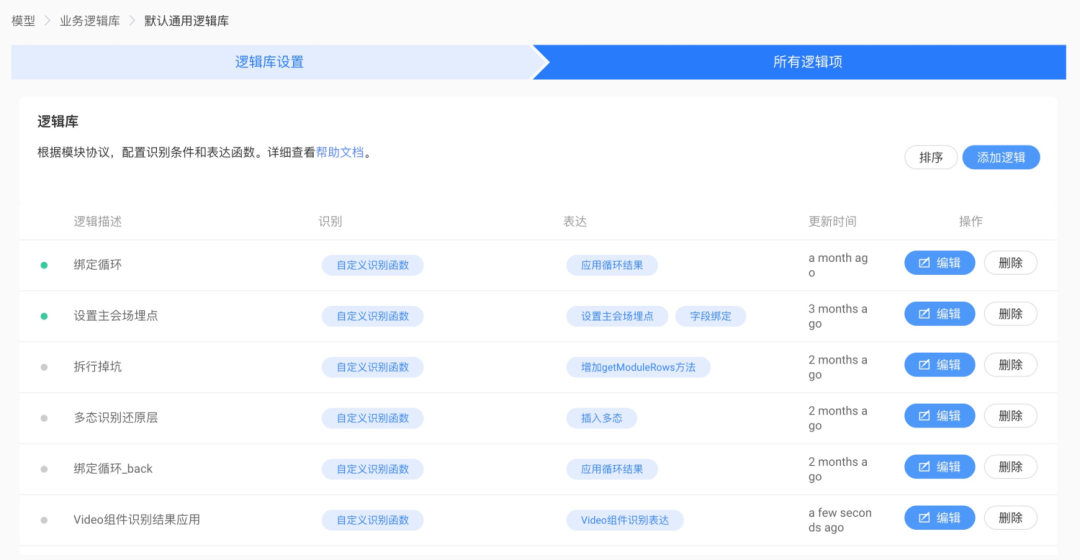
(通用业务逻辑库配置)
算法工程体系升级
样品制作机
算法工程服务提供了针对UI特征识别的模型训练产品,为所有想使用业务组件识别玩转机器学习的伙伴打下基础。为了解决算法工程服务使用的关键痛点,推出了新的衍生产品:样例制作器,为前端UI识别的模型提供了样例制作的快捷方式。
前端算法工程框架
很多同学认为让前端工程师使用机器学习技术解决前端问题比较困难,为了降低前端工程师使用机器学习的门槛,我们开发了前端算法工程框架来完成机器学习任务。
通过提供图像分类、物体检测、文本分类等通用模型能力,降低了这些模型开发和上线的门槛,让如此大量的底层识别能力能够快速迭代,比如部件识别、图标识别、字段语义识别等识别能力都是基于训练的。
(前端算法工程框架)
我们可以这么理解:Node.js的出现让前端工程师成为服务端工程师,做服务端工程师能做的事情,Node.js的出现让前端工程师成为机器学习工程师,做机器学习工程师能做的事情。

(前端和机器学习)
如何使用 Node.js 连接机器学习生态系统及其当前应用程序
研发链路升级
天马模组研发链接
淘宝营销以模块开发为主,模块开发完整链路为从模块管理平台创建模块⇥进入平台智能生成代码&可视化研发⇥开发完成后进入IDE调试预览⇥测试完成后进入工程平台发布,流程需要在多个平台间切换,开发链路体验和工程效率有待提升。
创建模块后,进入平台智能生成代码,可视化研发,如果能在平台上直接开发、调试、预览、发布,一站式D2C研发模式是提升整体研发效率和研发体验的不错选择。
因此我们定制了营销版可视化编辑器,具有可视化模式和源代码模式,在可视化模式下可以智能生成代码可视化研发,并将生成的代码一键同步到源代码模式;在编辑器中可以支持接口调试、预览、发布。

(天马模组视觉研发线)
通过计算采用传统研发模式开发的模块与采用可视化研发模式开发的模块的效率值(复杂度与研发时间比),我们发现,采用可视化研发链开发的模块编码效率提升了68%。
(天马模组视觉研发全链路演示)
Smart UI研发链接
智能UI是通过分析用户特征,为用户提供个性化UI的解决方案,因此需要开发大量的UI界面,淘宝智能UI平台精米中开发智能UI的原本环节是在上传视觉稿、解析素材之后,会批量创建模块,但每个素材都需要在对应的视觉界面中单独开发、入库、发布,无法看到智能UI的整体视觉效果,这导致对于智能UI所需要的大量素材,开发成本较高,企业接入智能UI的成本也较高。
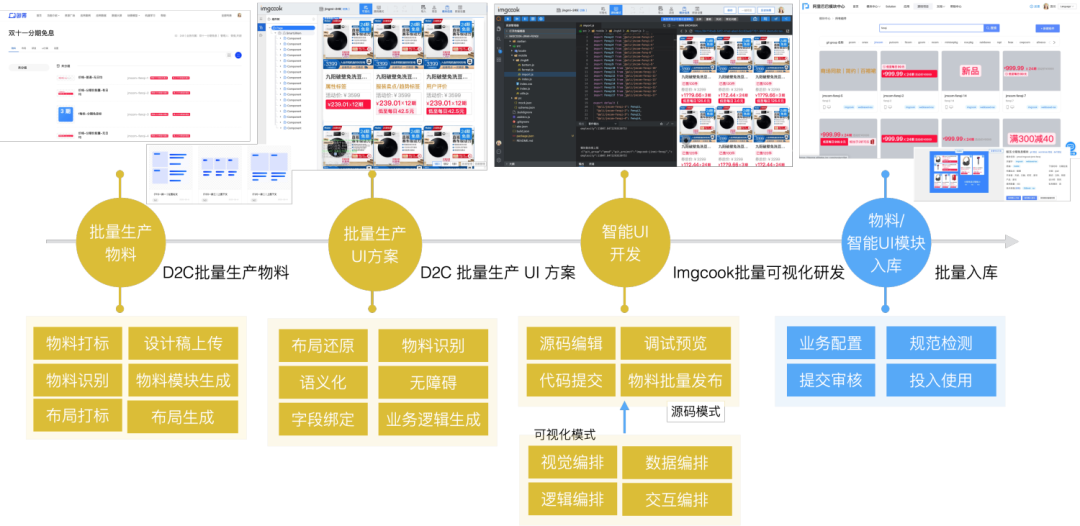
(智能UI可视化研发流程)
此次智能UI研发链全面升级,D2C可视化研发链接手智能UI量产,从上传设计稿、解析UI素材到创建模块,批量生成素材UI代码,同时创建代码仓库和模块,支持批量导入创建好的素材,批量生成UI方案(不同类型的UI),在生成的UI方案中集中开发素材,最后支持素材批量发布,整个链路集中化,效率提升很多。
NO.4
结果
今年,前端智能助力前端研发模式升级,多个BU联合搭建了前端设计稿识别算法模型和数据集,并在双11现场规模应用。
设计稿代码生成技术体系的全面升级(如UI多态、直播视频组件、循环智能识别增强等),带来营销模块研发环节的产品升级:双十一会场90.4%(较去年提升)新模块智能生成代码。升级设计稿智能检查能力。统计范围内,79.26%的智能生成代码在无需人工协助的情况下实现保留和发布。
相比传统模块开发模式,使用设计稿代码生成技术后编码效率(模块复杂度与研发时间的比值)提升68%,固定人力单位时间模块需求吞吐量提升约1.5倍。
仍需要手动改代码的主要原因包括:循环无法识别、条件展示逻辑代码无法自动生成、字段绑定猜测错误(字段标准化程度较差)、业务特性所需的图片合并问题等等,这是接下来需要逐步改进的。
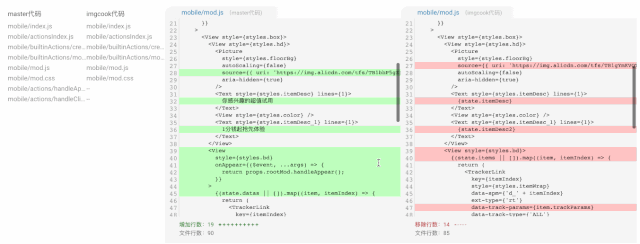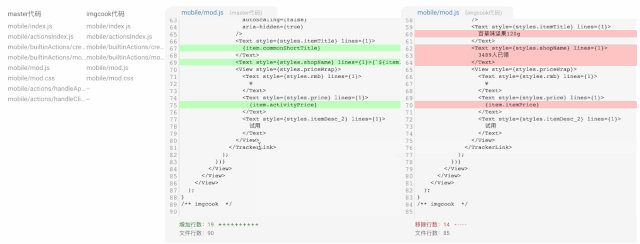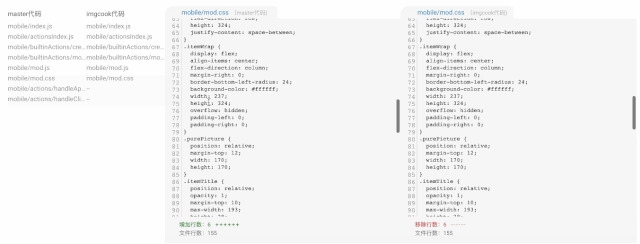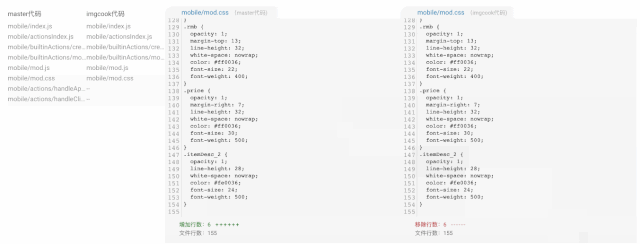
(D2C 代码生成用户变更)
同时支持天猫、淘宝主会场、行业会场智能UI的批量生产,大大提高智能UI的生产效率。
(Smart UI 量产成果)
5号
未来展望
无论是利用计算机视觉还是深度学习技术,智能方法都会存在准确率的问题,准确率低可能在线上环境下无法接受,需要建立与线上用户使用数据形成闭环的算法工程环节,实现样本自动化采集与算法工程的闭环,才能不断提升线上模型识别的准确率。目前在系统中,Icon识别已经形成了从样本采集到模型识别结果最终应用的完整闭环,没必要在模型优化上花费过多的精力。对于其他模型,未来也会用同样的思路,让模型具备自我迭代的能力。
D2C智能化的另一个难点是模型识别的结果最终如何用于生成代码,比如组件识别模型能识别出组件的类别,但最终生成的代码中到底用的是哪个组件库的组件,UI中如何识别组件的属性值,平台能力和智能还原技术分层架构有能力解决这些问题,未来也会有更多智能化方案应用于生产环境。
未来我们将在D2C智能能力分析的基础上继续探索更多的智能化解决方案,优化已有的模型能力,建立算法工程闭环机制,实现各个模型的自我迭代,不断提升模型的泛化能力、线性度,提升识别准确率,助力生成可维护性更高、语义更强的前端代码。
✿ 双十一系列
如有侵权请联系删除!

官方公众号
Copyright © 2023 江苏优软数字科技有限公司 All Rights Reserved.正版sublime text、Codejock、IntelliJ IDEA、sketch、Mestrenova、DNAstar服务提供商
Copyright © 2023 江苏优软数字科技有限公司 All Rights Reserved.正版sublime text、Codejock、IntelliJ IDEA、sketch、Mestrenova、DNAstar服务提供商
13262879759
微信二维码