
友好定价、专业客服支持、正版软件一站式服务提供
工作日:9:00-22:00

发布时间:2024-10-04
浏览次数:0
重组蛋白纯化准备:如何查找蛋白信息,从氨基酸序列中可以获得哪些纯化信息。
1.蛋白质信息和序列不清楚
案例1.1 如果基因和蛋白质序列均未知,则进行蛋白质纯化以获得其序列信息。
值得花费大量时间和精力来考虑来源(例如,器官、组织和培养细胞的类型)。应尝试各种来源的材料。应分析这些材料的蛋白质含量(每克起始材料的目标蛋白量或每单位提取的蛋白质消耗的起始材料量)、起始特定蛋白质活性(如果可能)或蛋白质稳定性等。如果可能,经典基于微生物独特生长要求的微生物分离方法可以取得意想不到的成功。 【蛋白质纯化指南】
案例 1.2 该蛋白质仅以名称为人所知。
您可以登录网站,通过蛋白ID号、蛋白全名、缩写等进行搜索,但要注意目标蛋白的物种来源和片段。
您还可以登录NCBI等网站查看蛋白质序列等信息(如下)。

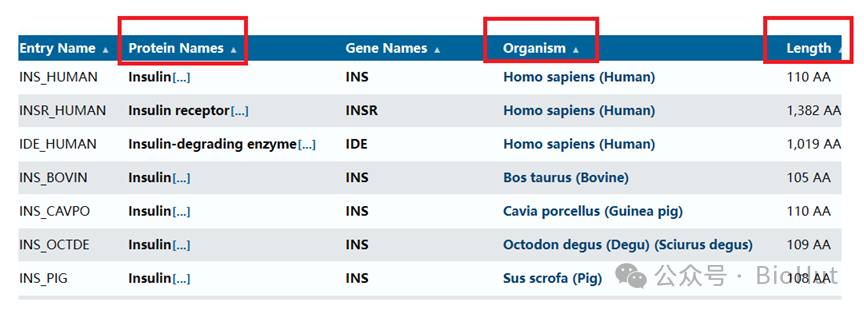
案例 1.3 该蛋白质只有已知序列。
您可以使用 NCBI 的 Blast 功能来比较序列,以锁定有关蛋白质的特定信息。
案例1.4 目标蛋白只有一个质粒。
通过测序(清除载体信息)可以得到蛋白质序列,这样就可以通过Blast来锁定。
2. 蛋白质基本特性的生物信息学资源检索
注:有关蛋白质的其他信息,请参考前两期的推文。
获得蛋白质氨基酸序列后,可以通过( )网站的.org/tools/部分进行搜索。操作如下:输入Swiss-Prot/TEMBL登录号(AC)或序列标识符(ID),或直接粘贴序列,然后点击“计算参数”按钮。

包括分子量(MW)、理论等电点(pI)、氨基酸组成()、元素组成()、消光系数()、预期半衰期(half-life)、不稳定系数(指数)、脂质溶解度指数(index)、总体平均亲水性指数(Grand of)等
还有其他软件或网站可以进行相关信息的检索和分析,例如(http://.com)等。
3. 氨基酸序列的重要信息和应用

3.1分子质量Molecular weight
粗略地说,就是蛋清有多大。后续分子筛纯化层析填料的选择还与检测中SDS-PAGE凝胶浓度的选择以及SEC-HPLC检测中层析柱的选择有关。
3.2 等电点pI
蛋白质静电荷为零时的 pH 值定义为其等电点 (pI)。当决定使用离子交换层析树脂纯化蛋白质时,pI 非常有用:
例如,如果假设蛋白质是单体,并且不存在会改变蛋白质电荷的修饰形式,则酸性蛋白质(pH 7 时带负电)倾向于与带正电的阴离子交换层析树脂结合,例如 Q -支柱。
碱性蛋白质(pH 7 时带正电)倾向于与带负电的阳离子交换树脂结合,例如 SP 柱。
[注 1:如果表面电荷分布不均匀dnastar序列比对,则此一般原则有例外。蛋白质表面可能同时存在多个正电荷积累区和多个负电荷积累区,这样在相同条件下,蛋白质既可以与阴离子交换柱结合,也可以与阳离子交换柱结合。
注2:一般情况下,蛋白质在pI时溶解度最小,因此如果纯化时不考虑等电点沉淀,则纯化过程中缓冲液的pH值应避开蛋白质的等电点pI,以防止蛋白质沉淀。 】

3.3 消光系数( )
未修饰蛋白质中含有的色氨酸、酪氨酸、苯丙氨酸在280 nm波长处有吸收值。
简而言之,如果某种蛋白质的A280 nm吸光度值理论上为1.45(1 mg/ml的A[280]=1.45),使用适当缓冲液的A280吸光度值作为对照,如果在1中测得的A280值为 0.75。事实上,您所测试的蛋白质溶液的浓度为0.75/1.45=0.52 mg/mL。

3.4 稳定性
从蛋白质序列可以预测蛋白质在体内的半衰期和不稳定指数。体内半衰期的计算基于蛋白质的N端原理和N端序列,可以估算出在哺乳动物细胞、酵母或大肠杆菌中表达的蛋白质的大致半衰期。
不稳定指数用于根据对蛋白质和一组已知稳定或不稳定的测试蛋白质中某种二肽的存在情况进行分析和比较来估计蛋白质的体外稳定性。当预测蛋白质在体外不稳定时,必须非常小心地在纯化过程中保持样品低温或向样品中添加蛋白酶抑制剂。
3.5 疏水区和跨膜区
疏水性预测
蛋白质跨膜螺旋在线分析工具
通过分析蛋白质的氨基酸序列,可以找到那些特别疏水或亲水的区域。这种方法使我们能够找到潜在的跨膜区域,并且对于功能未知的蛋白质,预测它们是否是膜蛋白。
注意:如果想使用原核表达系统进行表达,需要考虑删除跨膜区序列。

【硬货的纯化:截取影响蛋白表达的片段:如果你的序列中有影响重组表达的片段,而截断这个片段对后续应用不会有太大影响dnastar序列比对,理论上建议截断它以提高重组表达。成功率。
例如:如果你的重组蛋白想要在胞外表达纯化,但全长氨基酸序列的N端有一个强疏水区,你可以做一个小测试,看看是否剪掉N端疏水区区域和全长可以成功地分泌和表达它。 】
3.6 信号肽
喜欢。
信号肽通常具有相对疏水性,其主要功能是促进蛋白质分泌到细胞外。
在表达重组蛋白之前,需要预测序列的信号肽,然后根据信号肽预测结果删除、替换或添加信号肽。如果要使用原核表达系统进行表达,则需要考虑删除信号肽。
补充:目前蛋白质预测生物信息的链接有很多。国内外许多重组蛋白公司都整合了预测资源,将其整合到同一个网页中,展示多个项目的预测。这对每个人来说都很方便。
4. 无法从序列中预测的信息
设计纯化程序所需的大部分信息无法从氨基酸序列中预测。
4.1 蛋白质三维结构、形状和表面性质。
尽管结构预测(αfold等)发展迅速,但仍然无法确认预测结构的准确性,也无法预测蛋白质的形状或精确详细的表面特性,例如疏水区域分布、电荷分布、抗原位点等,这是非常困难的。很难预测其在疏水交换色谱或离子交换色谱中的行为,并且在不知道其形状的情况下无法预测其在凝胶过滤色谱中的行为。
4.2 多亚基特性——均聚物或杂聚物也是不可预测的。
即使我们能够准确预测蛋白质的三维结构,我们仍然无法预测该蛋白质在溶液中是以多聚体形式(例如六聚体)还是以单体形式存在。缺乏这些信息,无法合理预测其在分子筛或离子交换柱上的行为。更重要的是,一些蛋白质作为多亚基复合物的一部分存在。不可能预测纯化后蛋白质是否仍以复合物形式存在。如果是这样,它的净化特性可能很大程度上是由于与其结合。由其他亚基决定。
4.3 聚落属性
不同蛋白质的溶解度差异很大,其原因尚不清楚。因此,无法预测将使用什么浓度的沉淀试剂(硫酸铵、盐等)从溶液中沉淀出目标蛋白。
4.4 蛋白质稳定性和缓冲液稳定性
纯化后的蛋白质本身也存在保存、降解、稳定性差等问题。虽然大家对蛋白质和试剂缓冲液的了解越来越多,但目前还没有一种能够适应所有蛋白质/抗体的通用缓冲液(以后有时间再写一下蛋白质制剂的选择)。
借用老板的一句话:虽然掌握了蛋白质的序列信息,但是蛋白质纯化仍然是一个非常凭经验的工作!不用太担心,纯净了就没事了。
下一期:重组蛋白纯化实验设计及CIPP纯化策略
如有侵权请联系删除!

官方公众号
Copyright © 2023 江苏优软数字科技有限公司 All Rights Reserved.正版sublime text、Codejock、IntelliJ IDEA、sketch、Mestrenova、DNAstar服务提供商
Copyright © 2023 江苏优软数字科技有限公司 All Rights Reserved.正版sublime text、Codejock、IntelliJ IDEA、sketch、Mestrenova、DNAstar服务提供商
13262879759
微信二维码