
友好定价、专业客服支持、正版软件一站式服务提供
工作日:9:00-22:00

发布时间:2025-02-08
浏览次数:0
R1 API支持的本地知识库都是一个卑鄙的人。在深处践踏坑里之后,我发现了两个“残酷”的抹布真相。
问错误的问题=就像进入污水坑一样。我认为这是一个错误,但是我也收到了官方社区的“音乐会答案”来纠正我的观点。
在部署了 + R1的本地知识库解决方案之后,瘦新生A迅速使用春节假期,以简单,快速,新手和无代码压力的优势进行更多尝试和探索。
特别是sublime text自动保存,在尝试使用 +R1的本地知识库进行操作之后:
在等待了几种有效的实施方案之后,我对自己的出色能力感到惊讶。我突然感到 - “ AI可以从天堂起床。”
但是,当我们探索更深入的场景时,我们发现我们被“进入坑”。尤其是在阅读了主要平台上主要博客作者的文章之后,几乎所有这些都集中在“如何在专业开发人员领域中部署本地知识库并快速开始”或“抹布练习”,很少有人使用普通的纯粹用户。 “深入探索和分享应用程序技能。”
在下面,我将在当地知识库和相关的“抹布真相(2025年2月)中分享一些陷阱”
本文的内容:
1. 初始认知(误区)2. 怎么就“离开DeepSeek R1 API”的加持,本地知识库就是渣渣了?3. 为什么“AnythingLLM”打造的是本地知识库”,本地体现在哪里?4. 那怎样查看和查找本地结果呢?5. 问错问题=入天坑,有你中招的情况没?6. 不理解本地知识库的原理,以为是出Bug了……官方社区暖心答复7. 收货及思考:收货及思考
最初的认知(误会)
如前所述,在解锁了成功应用本地知识基础的四个经典之后,我突然感到:如果您获得了宝藏,LLM就在手中,而Rag可以做所有事情。
因此探索:
经过几次通过[场景繁殖] - [参数调整] - [结果比较分析] - [找到关系原理和过程] - [获得初步结论],发现了两个“残酷的真理”。
为什么“离开R1 API”的祝福?当地知识库是一巴掌吗?
当[场景繁殖]时,重点是对“产量数据分析洞察力”的繁殖和探索。由于受欢迎程度,它一直受到海外的攻击。直到今天(农历新年的第七天),API申请和使用功能尚未恢复。
部署了几个本地模型后,进行了比较尝试。
当通过本地模型重现其他几种方案时,获得的结果基本相同:很难匹配“ R1 API(通常称为:在线全血式版本R1)”的“几乎完美的性能”。
因此,我再次致敬:期待API的恢复并解锁更可靠的场景!
为什么“”创建一个“本地知识基础”,而当地区域在哪里反映?
总体而言,“本地”的表现是:知识是本地,大型模型是在本地部署的,在本地进行操作,并且结果在本地。
那么,您如何查看并找到本地结果? 1。当地对话记录
您可以通过小型扳手徽标的“配置”导出“工作区聊天历史记录” - “管理员” - “对话记录”以支持CSV和JSON格式。 Xiao A-Jun通常以JSON格式导出和文本打开视图(或IN)。

2。本地存储文件夹
所有存储的文件的地址是:c:\ users \ user \\ - \
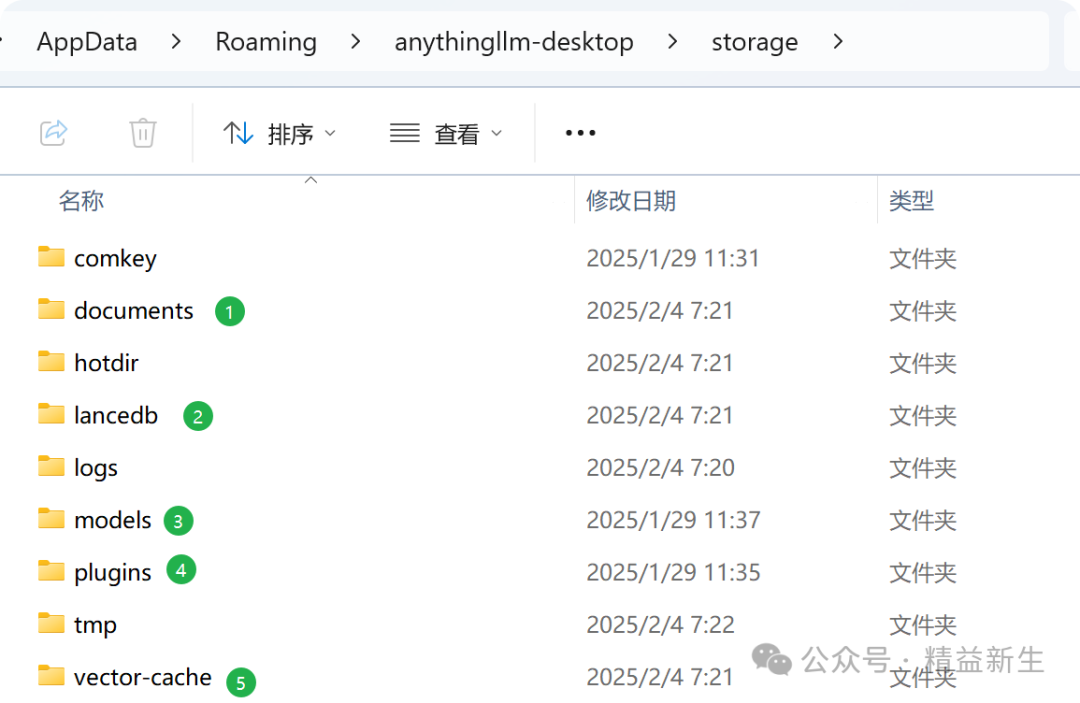
(1.7.x版)每个文件夹的存储内容被排序如下:
以下是本地存储文件夹中子文件夹的一个排序表,包括每个文件夹的功能和存储内容:
文件夹名称功能和存储内容
存储用户上传的文档文件的JSON文件切片。
[该向量数据库中的“数字”直接访问]文档的嵌入式向量()根据语义搜索和相似性匹配的工作区存储。
通过嵌入式推理或特定任务存储本地模型文件(例如语言模型,嵌入式模型等)。
日志
[基本上未查看]存储系统日志文件并记录运行时错误,警告和信息,以促进故障排除。
-缓存
上传工作空间后,此文件夹中存在带有“缓存”徽标的文件:它存储临时的缓存数据,例如文档片段或中间结果处理,以加快后续操作。
温度
在完成任务完成后,通常会自动清洁临时文件,例如下载文件或处理中的临时数据。
存储代理代理插件文件,用于扩展系统功能或集成第三方工具。
其中,在探索抹布时,最大的参考值(学习)值是缝制文件。例如,打开一个可以获得以下信息:

例如,
该文档对新手和初学者非常有帮助,以了解搜索生成的本地知识基础抹布增强的过程和逻辑。
问错误的问题=您是否有任何情况?
我遇到了以下所有情况:
一开始,我根本不了解当地知识库的原则,并认为这是一个错误...
经常遇到“文本截断”问题之后,我认为这是一个错误。 Xiao A的脸实际上在官方社区中发布了这个问题:
** [ - 实验室/-llm] [错误]:“ - for-”。
我提交的问题(让我跳过它们,这是如此基本,哈哈):
问:当我一个txt文件或pdf文件(书本或a的a或a)时,请使用(text块尺寸= 512,text块= 38),the,带有.i看到计数为100 -300。
当我问这个问题时,这是什么关键,其中有多少个单词?
多少?他们在哪里?
您可以在The中找到“ XXX”吗?
官方社区回答:
LLM也在抹布中。抹布,从根本上。
多少?他们在哪里?
再次,会全神贯注
您可以在The中找到“ XXX”吗?
这也将全文在抹布中,但是。
您阅读了有关工作的文档:#llms-do-not-
, - 不是一个,不是你。您的LLM并没有大大适合您的大型。如果我们只是让您将RAM锁定sublime text自动保存,而CPU将100%或LLM失败。
您将文本放入LLM中,甚至不是可以的。抹布(这是我们使用的)来缩小碎片,然后仅询问碎屑,并且对您的使用有意义。
这可以使用,但这是这些类型的“整体”。你问。
LLM不知道A是什么,它是什么样子,多少页,而不是文本。即使这样做的唯一方法是使用非常大的(2m)或 - 同样的sil l和许多人同时使用。因此为什么抹布。
这些内容可能值得部署本地知识库的新手 - 仔细研究和纠正认知。
接收商品和思维
在大型模型时代,好的问题比好的答案更好。
同样,本地知识库:提出错误的问题=进入坑并找到错误的对象。
经验:本地知识库似乎是“超级数据文员”,但不是“全文搜索者”,也不是“全方位决策者”。
充分利用它的核心在于:阐明边界,利用优势和避免弱点以及协调人机的界限。
您的使用良好吗?您有更好的本地知识基础解决方案吗?
欢迎为您的问题或经验留言,探索和共同取得进展。
如有侵权请联系删除!

官方公众号
Copyright © 2023 江苏优软数字科技有限公司 All Rights Reserved.正版sublime text、Codejock、IntelliJ IDEA、sketch、Mestrenova、DNAstar服务提供商
Copyright © 2023 江苏优软数字科技有限公司 All Rights Reserved.正版sublime text、Codejock、IntelliJ IDEA、sketch、Mestrenova、DNAstar服务提供商
13262879759
微信二维码