
友好定价、专业客服支持、正版软件一站式服务提供
工作日:9:00-22:00

发布时间:2023-11-17
浏览次数:0
上一篇文章介绍了分库分表的几种形式和方法,也重点介绍了垂直分库带来的问题和解决方案。 在这篇文章中,我们将讨论一些数据库和表水平分片的技术。
1、分片技术的起源。 关系数据库本身更有可能成为系统性能瓶颈。 单机存储容量、连接数、处理能力等都非常有限。 数据库本身的“有状态”特性使其不同于 Web 和应用程序服务器。 很容易扩展。 在互联网行业海量数据、高并发访问的考验下,聪明的技术人员提出了分库分表(有的地方也叫分片)技术。 同时,流行的分布式系统中间件(如等)都有自己的友好支持,其原理和思想都是相似的。 2、分布式全局唯一ID 在很多中小型项目中,我们经常直接利用数据库自增功能来生成主键ID,确实比较简单。 在分库分表环境下,数据分布在不同的分片上,不能直接利用数据库的自动增长特性生成数据,否则不同分片上的数据表主键会重复。 下面简单介绍一下使用和理解的几种ID生成算法。 1.(又名“雪花算法”)
2. UUID/GUID(一般应用程序和数据库都支持)
3.(类似UUID方法)
4.(数据库就是这样生存的)
3. 常用分片规则和策略分片字段如何选择
在开始分片之前,我们首先需要确定分片字段(也称为“分片键”)。 在很多常见的例子和场景中,都会使用ID或者时间字段来进行拆分。 这并不是绝对的。 我的建议是结合实际业务,对系统中执行的SQL语句进行统计分析,选择表中最常用或者最重要的需要分片的字段进行分片。 场地。
常见的分片规则
常见的分片策略包括随机分片和连续分片,如下图所示:
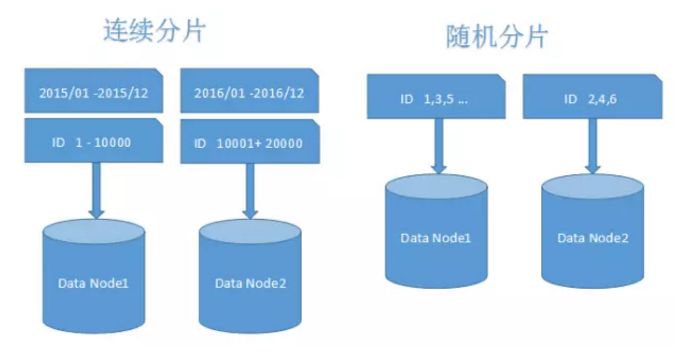
当需要使用分片字段进行范围搜索时,连续分片可以快速定位分片进行高效查询,并且大多数情况下可以有效避免跨分片查询问题。 如果后续想要扩展整个分片集群,只需要添加节点即可,不需要迁移其他分片的数据。 但连续分片也可能存在数据热点的问题。 就像图中按时间字段分片的例子一样,部分节点可能面临频繁的查询压力,热点数据节点成为瓶颈。 有些节点可能会存储历史数据,很少需要查询。
随机分片实际上并不是随机的,而是遵循一定的规则。 通常,我们使用Hash模来进行分片分裂,因此有时也称为离散分片。 随机分片的数据相对均匀,不易出现热点和并发访问瓶颈。 但后期分片集群的扩容需要旧数据的迁移。 使用一致性Hash算法可以很大程度上避免这个问题,所以很多中间件分片集群都会使用一致性Hash算法。 离散分片也容易出现跨分片查询的复杂问题。
数据迁移、容量规划、扩容等问题
很少有项目在早期就开始考虑分片设计,通常是在业务快速发展、面临性能和存储瓶颈时提前准备。 因此,不可避免地要考虑历史数据迁移的问题。 一般的做法是先通过程序读取历史数据,然后按照指定的分片规则将数据写入到各个分片节点。
另外,我们需要根据当前的数据量和QPS进行容量规划,并根据成本因素计算出大概需要的分片数量(一般建议单个分片上单表的数据量不宜超过超过1000W)。
如果采用随机分片,需要考虑后期的扩容问题,会比较麻烦。 如果使用范围分片,只需要添加节点即可自动扩容。
4. 跨分片技术问题 跨分片排序与分页
一般来说,分页时需要按照指定字段进行排序。 当排序字段为分片字段时,我们可以通过分片规则轻松定位到指定的分片。 但当排序字段为非分片字段时,情况就变得更加复杂。 为了保证最终结果的准确性,我们需要对不同分片节点中的数据进行排序返回,对不同分片返回的结果集进行汇总并重新排序,最后返回给用户。 如下所示:
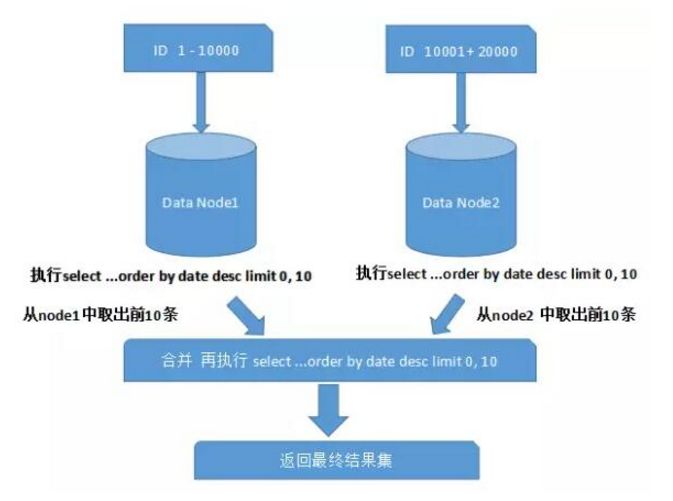
上图描述的只是最简单的情况(取第一页数据),看起来影响不大。 但如果要取出第10页的数据,情况就会变得复杂很多,如下图所示:
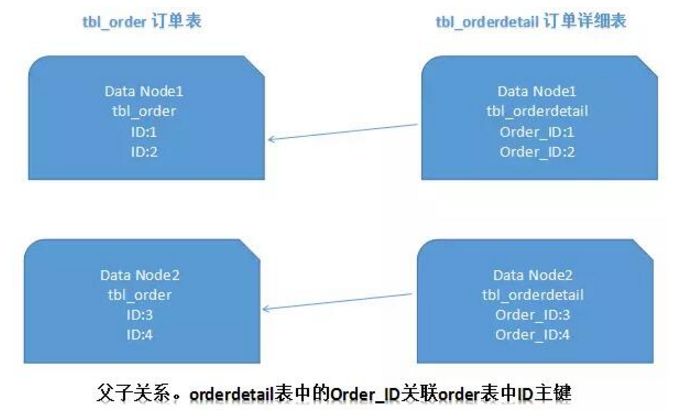
有些读者可能不太明白为什么不能像获取第一页数据那样简单处理(排序,取出前10条,然后合并排序)。 其实也不难理解,因为每个分片节点中的数据可能是随机的。 为了排序的准确性,必须对所有分片节点的前N页数据进行排序并合并,最后进行整体排序。 显然,这样的操作会消耗资源。 用户翻页越多,系统性能就越差。
跨分片功能处理
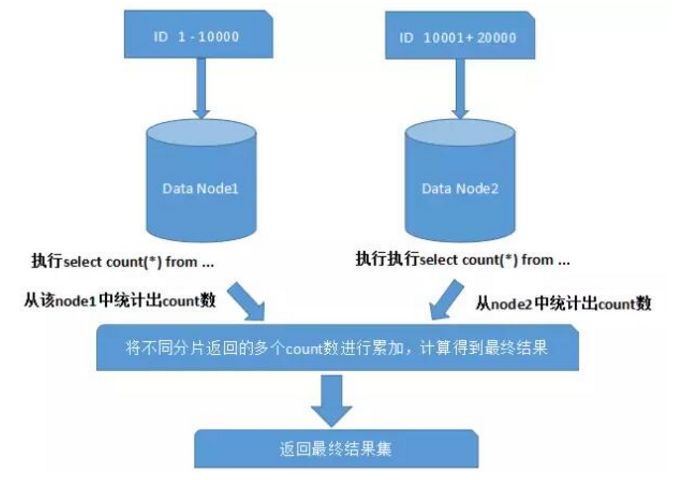
使用Max、Min、Sum、Count等函数进行统计和计算时intellij idea 数据库关系图,需要首先对每个分片数据源进行相应的函数处理,然后对每个结果集进行二次处理,最后返回处理结果。 如下所示:
跨分片连接
Join是关系数据库中最常用的功能,但在分片集群中,Join也变得非常复杂。 应尽可能避免跨分片联接查询(这种场景比上面的跨分片分页更复杂,并且对性能影响很大)。 通常有几种方法可以避免:
全局表
全局表的概念之前在《垂直分库》中提到过。 基本思想是一样的,就是把一些类似于数据字典的、可能产生join查询的表信息放到每个shard中,从而避免跨shard join。
ER 分片
在关系型数据库中,表与表之间往往存在一些相关关系。 如果我们能够先确定关联,并将关联的表记录存储在同一个分片上,就可以避免跨分片连接问题。 在一对多关系的情况下,我们通常选择按照数据多的一方进行拆分。 如下所示:
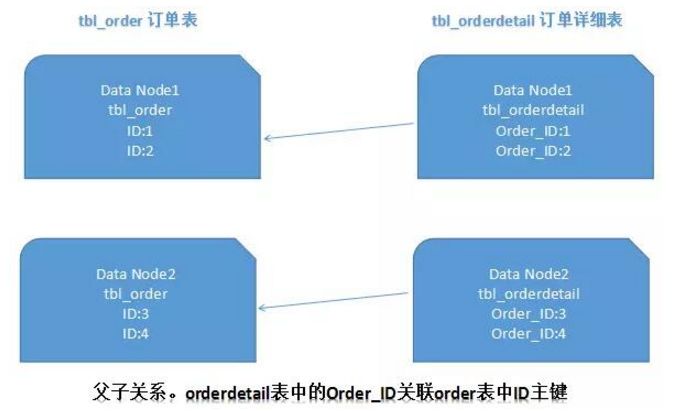
这样,Data Node1上的订单表和订单明细表就可以直接关联起来进行本地连接查询,Data Node2上也是如此。 这种基于ER分片的方式可以有效避免大多数业务场景下的跨分片连接问题。
内存计算
随着Spark内存计算的兴起,从理论上来说,很多跨数据源的操作问题似乎都可以得到解决。 数据可以扔到spark集群进行内存计算,最后返回计算结果。
5. 跨分片交易问题 跨分片交易也是分布式交易。 如果想了解分布式事务,就需要了解“XA接口”和“两阶段提交”。 值得一提的是,.5x和5.6x中xa支持存在问题,会导致主从数据不一致。 直到 5.7x 版本才修复。 Java应用程序可以使用框架来实现XA事务(J2EE中的JTA)。 有兴趣的读者可以自行参考《分布式事务一致性解决方案》,链接地址:
6、我们的系统真的需要分库分表吗? 看完上面的内容intellij idea 数据库关系图,有的读者不禁会想,我们的系统需要分库分表吗?
事实上,这一点并没有明确的判断标准,更多地依赖于实际业务情况和经验。 根据笔者的个人经验,一般MySQL单表1000万左右的数据是没有问题的(前提是应用系统和数据库设计和优化得当)。 当然,除了考虑当前的数据量和性能之外,作为架构师,我们还需要提前考虑系统半年到一年左右的业务增长情况,对QPS、连接数等做出合理的评估和规划数据库服务器的情况、容量等,并提前做好相应的准备。 如果单台机器无法满足要求,并且很难从其他方面进行优化,那么就需要考虑分片。 这种情况下,可以先删除数据库中的自增ID,为分片和后续数据迁移做准备。
很多人认为“分库分表”宜早不宜迟,因为担心以后公司业务发展更快,系统变得更加复杂,系统改造和扩容会影响公司的业务。更难……这听起来似乎有一定道理,但我的观点却恰恰相反。 对于关系型数据库,我认为“不能分片就不分片”,除非系统确实需要,因为数据库分片并不是低成本或者免费的。
这里笔者推荐一种更靠谱的过渡技术——“表分区”。 主流关系数据库基本支持。 不同分区逻辑上仍然是一张表,但物理上是分开的,可以在一定程度上提高查询性能,并且对应用程序透明,无需修改任何代码。 作者曾经负责优化一个系统。 主业务表有8000W左右的数据。 考虑到成本问题,当时采用的是“表分区”。 效果明显,系统运行非常稳定。
7.总结 最后,很多读者想了解社区是否有开源、免费的分片解决方案。 毕竟,站在巨人的肩膀上,可以省去很多力气。 目前解决方案主要有两类:
1、基于应用层的DDAL(分布式数据库访问层)
比较典型的有淘宝的半开源TDDL、当当的开源-JDBC等,分布式数据访问层不需要硬件投入。 技术能力较强的大公司通常会选择自研或者参考开源框架进行二次开发和定制。 它通常对应用程序更具侵入性,并增加技术成本和复杂性。 通常只支持特定的编程语言平台(多为Java平台),或者只支持特定的数据库和特定的数据访问框架技术(一般支持MySQL数据库、JDBC等框架技术)。
2、数据库中间件,典型的有mycat(在阿里开源cobar的基础上做了很多优化和改进,是后起之秀,也支持很多新功能),基于Go语言实现,还有比较老的Atlas(开源360)等待。 这些中间件在互联网公司中得到广泛应用。 另外,MySQL 5.x企业版中官方提供的组件也声称支持分片技术,但国内很少有公司使用。
中间件也可以称为“透明网关”,最著名的可能就是这个领域的鼻祖(由MySQL官方提供,仅限于实现“读写分离”)。 中间件一般实现特定数据库的网络通信协议,模拟真实的数据库服务,屏蔽真实的后端。 应用程序通常直接连接到中间件。 执行SQL操作时,中间件会根据预定义的分片规则对SQL语句进行解析和路由,并对结果集进行二次计算并最终返回。 引入数据库中间件的技术成本较低,对应用几乎无侵入,可以满足大多数业务。 这就增加了额外的硬件投资和运维成本。 同时,中间件本身也存在性能瓶颈和单点故障。 需要保证中间件本身的高可用性和可扩展性。
总之,无论是使用分布式数据访问层还是数据库中间件,都会带来一定的成本和复杂度,同时也会带来一定的性能影响。 因此,读者需要根据实际情况和业务发展需要仔细考虑和选择。
近期值得阅读的热门文章:
1、
2、
3.
4.
5.
6.
7.
8、
9、
10.
关注公众号,你想要的Java这里都有
如有侵权请联系删除!

官方公众号
Copyright © 2023 江苏优软数字科技有限公司 All Rights Reserved.正版sublime text、Codejock、IntelliJ IDEA、sketch、Mestrenova、DNAstar服务提供商
Copyright © 2023 江苏优软数字科技有限公司 All Rights Reserved.正版sublime text、Codejock、IntelliJ IDEA、sketch、Mestrenova、DNAstar服务提供商
13262879759
微信二维码