
友好定价、专业客服支持、正版软件一站式服务提供
工作日:9:00-22:00

发布时间:2023-11-27
浏览次数:0

当研究 DNA 或蛋白质序列时,主要关注的是它所包含的遗传信息; 当研究两个或多个DNA或蛋白质序列时,主要关注的是不同序列之间的差异和联系。 在生物信息学中,生物大分子的序列比对是一项非常基本的任务。
目前进化论的基本思想是生物结构由简单到复杂,物种由少到多。 在生命的进化过程中,DNA可能会发生突变(碱基替换)、插入、缺失等变化,使得不同物种的DNA序列既相似又不同。 序列比较()的主要思想是使用特定的算法来找到在两个或多个序列之间产生最大相似度得分的空间插入和序列排列方案。 主要要解决的问题是DNA序列的插入和缺失变化。 。 根据比对序列的数量,可分为双序列比对( )和多序列比对( )。 序列比对主要基于动态规划算法(动态规划算法),揭示序列中的保守区和非保守区,分析序列的进化趋势。
描述序列之间关系的概念包括同源性()、相似性()和距离()。 同源性是一个定性的概念,意味着不同的序列有共同的进化祖先; 相似度和距离都是定量概念,表示两个序列之间的相似程度和差异程度。 如果两个序列同源,则它们具有很高的相似性,但由于趋同进化( )的存在,高相似性并不一定意味着它们是同源的。
同源性可分为垂直同源性()和水平同源性()。 垂直同源性是共同祖先的不同进化分支。 水平同源性主要是由基因组复制事件产生的,例如动物α-珠蛋白和β-珠蛋白的同源性。 关系如下:
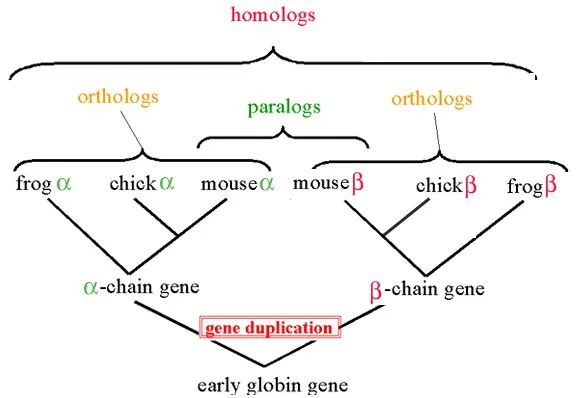
直向同源物通常具有相同或相似的功能,但旁系同源物不一定如此:缺乏自然选择的原始力量,重复的基因副本可以更自由地突变并获得新的功能。
相似度得分和距离是一对相反的变量,定量描述序列相似度和距离。 相似性得分是在一定评分规则下两个序列的对应字符的函数。 一般来说,相同的字符(即碱基或氨基酸)越多,得分越高dnastar序列比对,如下图:
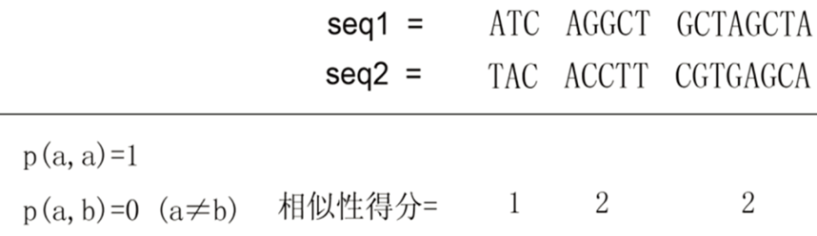
然而,在进化过程中,除了碱基替换之外,还存在插入、删除、重复等,因此,相似性描述序列的主要思想是通过在序列中插入空格来获得最高的相似性分数(score)。序列:

其中,s1',s2'...sk'是在序列s1,s2...sk中插入空格得到的。
编辑距离的值取决于两个序列对应位置处不同字符的数量。 不同的角色越多,价值就越大。 例如,汉明距离 ( ) 计算如下:

距离描述序列的主要思想是通过字符替换将一个序列转换为另一个序列。 每次替换都记录为成本。 考虑到插入和删除的存在dnastar序列比对,该操作还可以扩展到字符替换和空格插入。 ,去除空格,因此多个序列之间的距离的描述就是将这些序列转换为公共序列所需的最小成本:

如果不包括插入和删除的空格,只计算对应字符的替换成本,则为编辑距离(edit)。
结尾
如有侵权请联系删除!

官方公众号
Copyright © 2023 江苏优软数字科技有限公司 All Rights Reserved.正版sublime text、Codejock、IntelliJ IDEA、sketch、Mestrenova、DNAstar服务提供商
Copyright © 2023 江苏优软数字科技有限公司 All Rights Reserved.正版sublime text、Codejock、IntelliJ IDEA、sketch、Mestrenova、DNAstar服务提供商
13262879759
微信二维码